Détecter des communautés dans un graphe de dépendances

Au fur et à mesure qu'une application grandit, comprendre sa structure devient toujours de plus en plus difficile : les dépendances s'accumulent, les frontières entre modules se brouillent lentement.
Comment savoir si notre architecture est toujours cohérente ou si elle a dérivé sans qu'on s'en rende compte ?
Le premier réflexe sera de visualiser les dépendances de l'application, comment les classes et les composants interagissent entre eux, mais comprendre si ces dépendances forment des groupes cohérents est une question autrement plus complexe.
C'est précisément ce que permet la détection de communautés et c'est ce que nous allons explorer à travers l'algorithme de Louvain.
Les graphes de dépendances
Avant d'aborder l'algorithme de Louvain, il est nécessaire de poser quelques bases sur ce qu'est un graphe de dépendances et ce qu'il nous apprend de notre code.
Un graphe de dépendances est une représentation visuelle des relations entre les classes d'une application. Chaque classe est un nœud et chaque dépendance entre deux classes est une arête reliant ces deux nœuds :
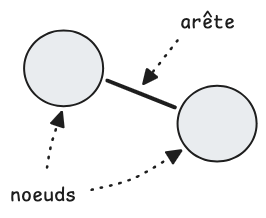
Sur une application de très petite taille, un graphe de ce genre resterait lisible et les relations faciles à appréhender. Mais dès lors que votre projet grossira, ce graphe deviendra très rapidement difficile à lire, voire quasiment inexploitable.
Une application Laravel de taille intermédiaire peut facilement atteindre plusieurs centaines de classes ... et donc plusieurs milliers d'arêtes !
 Graphe réel d'une application de plusieurs centaines de classes
Graphe réel d'une application de plusieurs centaines de classes
À cette échelle, le graphe devient un enchevêtrement dense dans lequel il est impossible de distinguer ce qui est intentionnel de ce qui est accidentel ... voire même d'y percevoir quoi que ce soit.
Une solution de contournement consiste à visualiser non pas les classes mais les dossiers qui devraient, dans une application bien structurée, faire apparaître les modules ou composants :
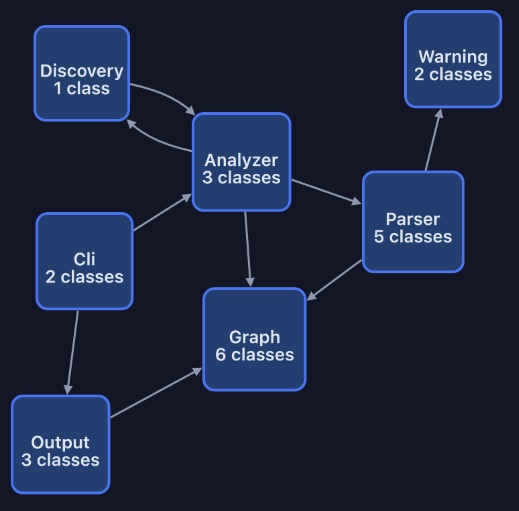 Graphe macro obtenu par le package DeGraciaMathieu/php-dep-dashboard
Graphe macro obtenu par le package DeGraciaMathieu/php-dep-dashboard
Ce niveau de granularité est certes plus lisible et exploitable mais conserve une contrainte non négligeable : il ne révèle pas les tensions réelles entre groupes de classes situés à des niveaux différents de l'arborescence.
Ce type de graphe reste donc utile pour appréhender les flux entre les modules de l'application, mais insuffisant pour comprendre ce qui se passe à l'intérieur.
Dans ces conditions, la question de la cohésion architecturale devient difficile à trancher : on sait que les classes dépendent les unes des autres ... mais on ne sait pas vraiment si ces dépendances forment des groupes cohérents ou si elles sont le fruit d'un couplage non maîtrisé.
Détecter des communautés
Dans un graphe de dépendances, une communauté désigne un groupe de nœuds qui interagissent davantage entre eux qu’avec le reste du graphe.
En d'autres termes, ce sont des classes qui se connaissent beaucoup, qui s'appellent mutuellement et qui semblent former un ensemble cohérent du point de vue des dépendances :
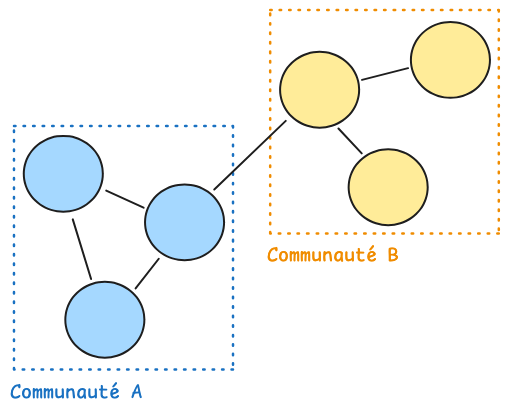
Dans une application bien structurée, on s'attend à ce que les communautés détectées correspondent à des clusters fonctionnellement cohérents : des groupes de classes qui ont une raison métier de se parler, qu'elles appartiennent au même module ou à des modules naturellement liés.
La détection de communautés consiste donc à vérifier si ce couplage est intentionnel et fonctionnellement justifiable, sans se fier uniquement à l'organisation des dossiers ou aux intentions initiales de l'architecture.
Cette distinction est importante car l'organisation en dossiers reflète ce que l'on voulait construire tandis que les communautés reflètent ce que le code construit réellement ... et ces deux réalités ne coïncident pas toujours.
Détecter des communautés peut alors révéler plusieurs situations intéressantes :
Une communauté regroupant des classes dont le couplage est fonctionnellement justifiable est une bonne nouvelle : que ce soit des classes d'un même module ou de modules naturellement liés, le couplage observé reflète une intention cohérente.
Une communauté qui regroupe des classes de modules sans lien fonctionnel évident est un signal d'alerte : ces classes interagissent davantage avec l'extérieur qu'avec leur propre module ou contexte fonctionnel, ce qui peut trahir un couplage non intentionnel.
Des classes isolées sans communauté claire signalent souvent une appartenance fonctionnelle ambiguë : des classes utilitaires trop génériques, des abstractions mal positionnées, ou tout simplement des éléments qui n'ont pas encore trouvé leur place dans l'architecture.
L'algorithme de Louvain
Maintenant que nous en savons davantage sur la théorie des communautés, intéressons nous à l'algorithme.
L'algorithme de Louvain fut publié en 2008 par Vincent Blondel à l'Université catholique de Louvain, l'algorithme est réputé pour sa rapidité et sa capacité à produire des résultats interprétables.
Il fut à l'origine conçu pour étudier des réseaux sociaux et des graphes de grande échelle et non à analyser du code.
C'est Jean-François Lépine, créateur de PHPMetrics, qui eut l'idée de l'appliquer aux dépendances dans son outil ast-metrics, avec l'intuition que les classes d'une application se comportent finalement comme n'importe quel réseau : des nœuds qui s'attirent, forment des groupes et révèlent une structure.
Concrètement, l'algorithme cherche à maximiser la modularité du graphe : trouver un découpage tel que les classes d'un même groupe dépendent davantage les unes des autres que des classes situées dans les autres groupes.
En d'autres termes, les dépendances à l'intérieur d'une communauté doivent l'emporter clairement sur les dépendances qui en sortent.
Voyons comment il procède plus en détails.
Mesurer la qualité du découplage avec la modularité
Chaque phase de l'algorithme de Louvain va chercher à maximiser un même indicateur : la modularité (notée Q).
Cette modularité est un score compris entre -1 et 1 qui mesure la qualité d'un découpage en communautés.
Plus Q est proche de 1, plus les communautés détectées sont denses en interne et peu connectées entre elles. Au-delà de 0.3, on considère généralement que la structure communautaire est importante.
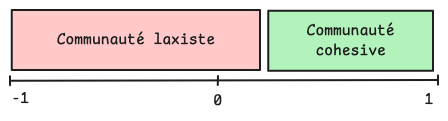
Cette notion de modularité peut être difficile à cerner alors essayons de la représenter pour y voir plus clair.
Dans l’exemple suivant, les classes forment deux communautés distinctes, mais ces dernières restent fortement liées entre elles.
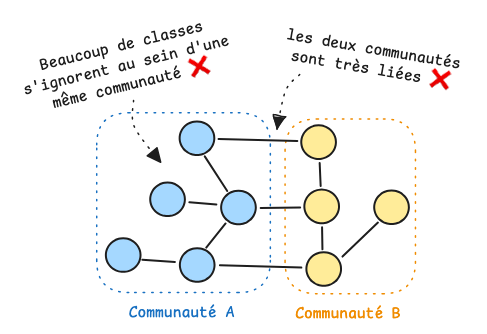
À l’intérieur de ces groupes, les classes présentent peu de cohésion : beaucoup ne dépendent pas les unes des autres, la modularité associée à ce découpage est donc faible.
À l’inverse, dans l’exemple suivant, les deux communautés sont très peu connectées entre elles et les classes qu’elles contiennent interagissent fortement : chaque groupe est dense et cohésif ce qui conduit à une modularité élevée.
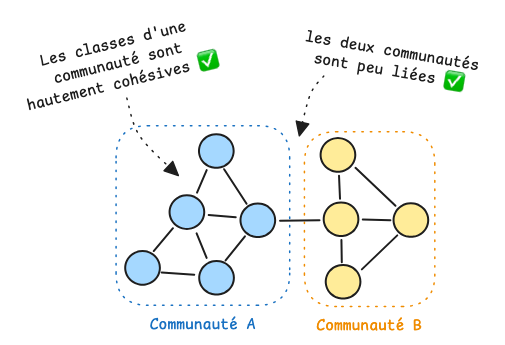
C'est exactement ce que l'algorithme de Louvain cherchera à maximiser durant ses différentes phases : il va progressivement associer les classes entre elles pour former des communautés denses en interne et le plus isolées possible les unes des autres.
Phase 1 : Chaque classe cherche sa meilleure communauté
Au départ, chaque nœud du graphe forme sa propre communauté, on a donc autant de communautés que de classes :
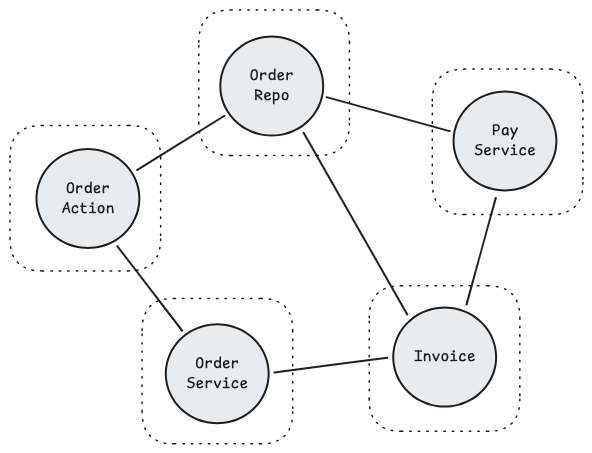
L'algorithme parcourt ensuite tous les nœuds un par un, pour chaque nœud, il pose une question simple : est-ce que je gagnerais en modularité si je rejoignais la communauté de l'un de mes voisins ?
Il calcule alors le gain de modularité que produirait ce déplacement vers chaque communauté voisine, si un gain positif existe, le nœud rejoint la communauté qui maximise ce gain, sinon, il reste seul :
L'algorithme répète cette opération pour tous les nœuds, encore et encore, jusqu'à ce qu'aucun déplacement ne permette d'améliorer la modularité, on dit alors que la phase 1 a convergé :
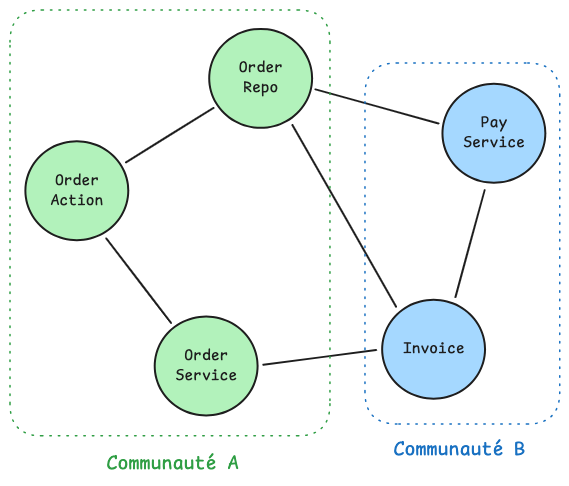
Chaque nœud appartient désormais à une communauté : la phase 1 a terminé son travail. La phase 2 peut alors commencer, elle va condenser ces communautés en super nœuds pour recommencer le même processus à une échelle supérieure.
Phase 2 : Les communautés deviennent des super-nœuds
Une fois la phase 1 terminée, chaque communauté détectée est condensée en un seul nœud. Les arêtes entre deux communautés deviennent une arête entre les deux super-nœuds correspondants :
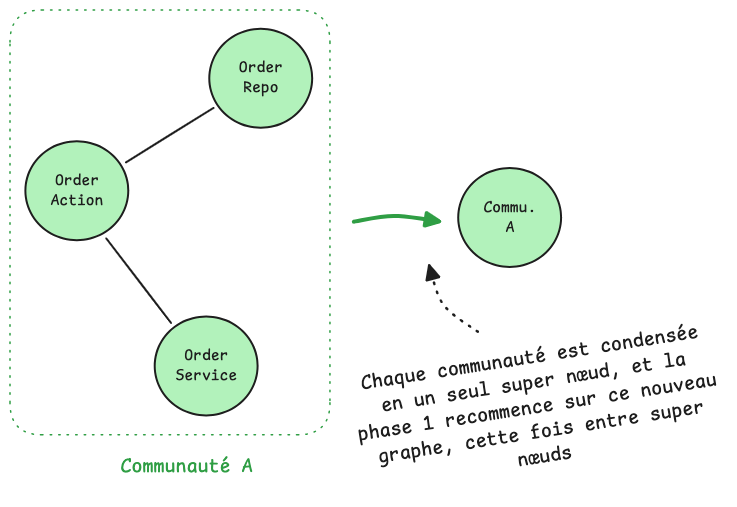
On obtient ainsi un nouveau graphe, beaucoup plus petit que l'original, sur lequel on relance la phase 1 depuis le début.
Ce nouveau graphe est plus simple mais il préserve l'information essentielle : les dépendances existantes entre les nœuds.
L'algorithme peut donc continuer à chercher des structures de plus haut niveau, des groupes de groupes, avec le même mécanisme.
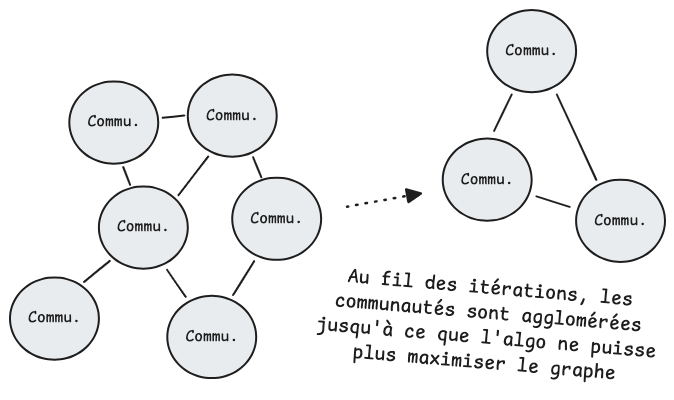
Ces deux phases alternent jusqu'à ce que plus aucune amélioration ne soit possible, ni au niveau des nœuds individuels, ni au niveau des super-nœuds, l'algorithme s'arrête alors et retourne le découpage final.
En pratique, la convergence est atteinte en peu de niveaux, ce qui explique les bonnes performances de l'algorithme même sur de très grands graphes.
Ce que la détection révèle d'une architecture
La théorie étant posée, voyons ce que cela donne en pratique sur une application Laravel.
Imaginons une application de ecommerce organisée en plusieurs modules, chaque module possedant ses propres actions, entités, repositories et services.
Cas 1 : Les communautés confirment les modules
Dans le meilleur des cas, l'algorithme retourne des communautés dont le regroupement fait sens fonctionnellement : soit des classes d'un même module, soit des classes de modules naturellement liés par un même domaine fonctionnel.
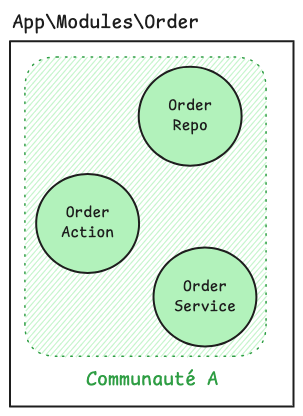 La communauté est cohérente avec le module
La communauté est cohérente avec le module
C'est la confirmation que le couplage observé est intentionnel : les classes qui ont une raison métier de se parler sont effectivement les plus couplées entre elles, l'architecture voulue et la réalité du code sont alignées.
Ce résultat n'est pas anodin : il valide que les dépendances qui se sont accumulées au fil du développement restent fonctionnellement cohérentes, malgré les évolutions et les ajouts successifs.
Cas 2 : Les communautés révèlent un couplage non intentionnel
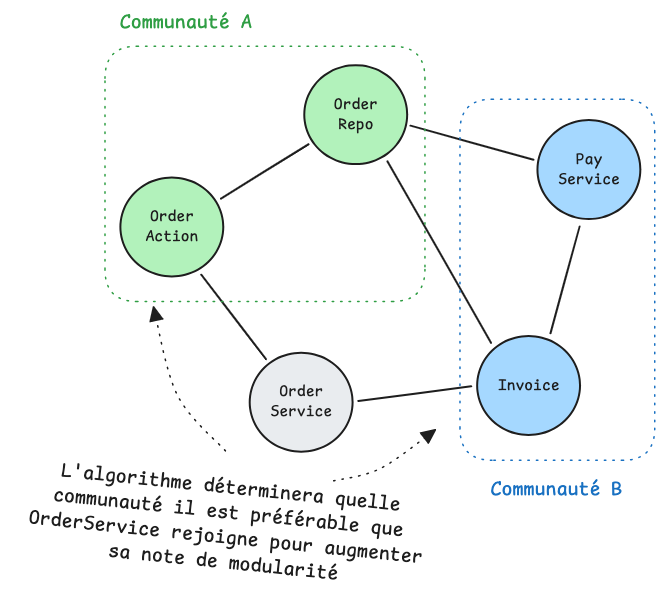
Maintenant, imaginons que l'algorithme retourne une communauté regroupant des classes du module Order et du module Notification :
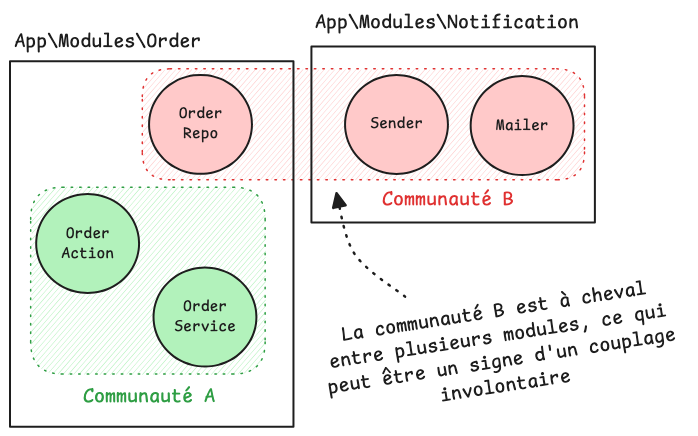
Si l'algorithme place OrderRepository dans la communauté Notification plutôt que dans celle d'Order, c'est qu'elle interagit davantage avec les classes de ce module qu'avec celles du sien.
Cette situation est avant tout une observation : cette classe est fonctionnellement plus proche de Notification que d'Order, la question n'est alors pas seulement de savoir si elle est au bon endroit, mais également de savoir si elle a les bonnes responsabilités.
Ce type de couplage est souvent involontaire et progressif : il s'installe discrètement, fonctionnalité après fonctionnalité, jusqu'à ce que les modules ne soient plus vraiment indépendants ni cohérent.
Cas 3 : La classe sans appartenance claire
Enfin, certaines classes peuvent se retrouver dans des communautés de petite taille ou former des communautés isolées, cela sera souvent le signe d'une classe très générique, peu couplée à un contexte fonctionnel particulier :
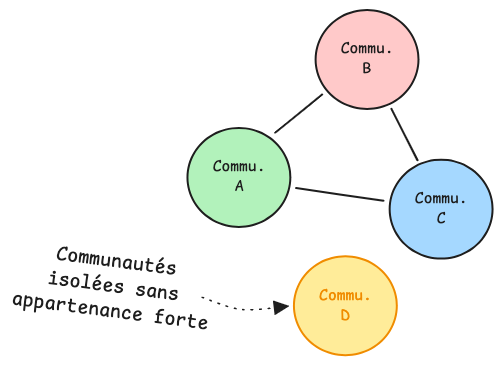
Une classe utilitaire comme StringHelper ou DateFormatter peut légitimement se retrouver dans cette situation : elle est appelée par tout le monde et n'appartient fonctionnellement à personne.
Cependant, une classe OrderRepository isolée de son module sera en revanche un signal plus problématique : est-ce que cette classe a trouvé sa vraie place dans l'architecture ?
Le score de modularité comme indicateur global
Au delà des communautés elles mêmes, le score de modularité retourné par l'algorithme offre un indicateur global sur la cohésion de l'architecture.
Un score élevé (au-dessus de 0.4) indique que les communautés sont bien séparées et peu couplées entre elles, une bonne nouvelle sur une application modulaire.
Un score plus faible (en dessous de 0.2) indique que les dépendances sont uniformément distribuées dans le graphe sans structure communautaire claire : le signe d'un couplage fort et diffus.
Ce chiffre seul n'est pas une vérité architecturale, mais il devient intéressant à suivre dans le temps : une baisse progressive du score de modularité peut signaler que le couplage s'intensifie discrètement, que l'entropie progresse, et que votre système devient de plus en plus rigide et difficile à faire évoluer.
Les limites à garder en tête
L'algorithme de Louvain est un outil puissant mais ces résultats sont avant tout des indicateurs et non des vérités absolues, il est nécessaire de toujours les interpréter avec du recul.
L'algorithme raisonne uniquement sur la structure des dépendances et non sur leur sens fonctionnel.
Deux classes peuvent être fortement couplées pour de mauvaises raisons : l'algorithme les regroupera tout de même ensemble car la détection révèle une réalité du code et non une intention.
Une application peut obtenir un score de modularité élevé avec des modules parfaitement cohésifs mais dont les frontières fonctionnelles sont complètement incohérentes : l'algorithme mesure la cohésion structurelle du graphe et non la pertinence du découpage métier.
Lorsque deux découpages produisent une modularité très proche, l'ordre de parcours des nœuds peut influencer le résultat final. Cet effet reste marginal, mais il faut garder à l'esprit que deux exécutions successives peuvent produire des communautés légèrement différentes.
La détection de communautés est donc un point de départ pour l'investigation et non une conclusion définitive.
Elle permet d'identifier des zones à examiner mais la réponse à ces questions sera toujours dans le code lui même et l'intention que vous voulez donner à l'architecture.
Comment calculer les communautés
Cet article a volontairement mis de côté les formules mathématiques qui sous tendent l'algorithme de Louvain, le calcul exact du score de modularité, la gestion des poids d'arêtes, la convergence, afin de se concentrer sur l'essentiel : comprendre ce que l'algorithme cherche à faire et ce que ses résultats nous apprennent sur une architecture.
Si vous souhaitez aller plus loin et expérimenter par vous même, il existe des outils accessibles pour visualiser ces communautés sur des projets PHP.
Pour une première visualisation rapide des communautés, php-dep-louvain permet d'obtenir un résultat exploitable en quelques minutes.
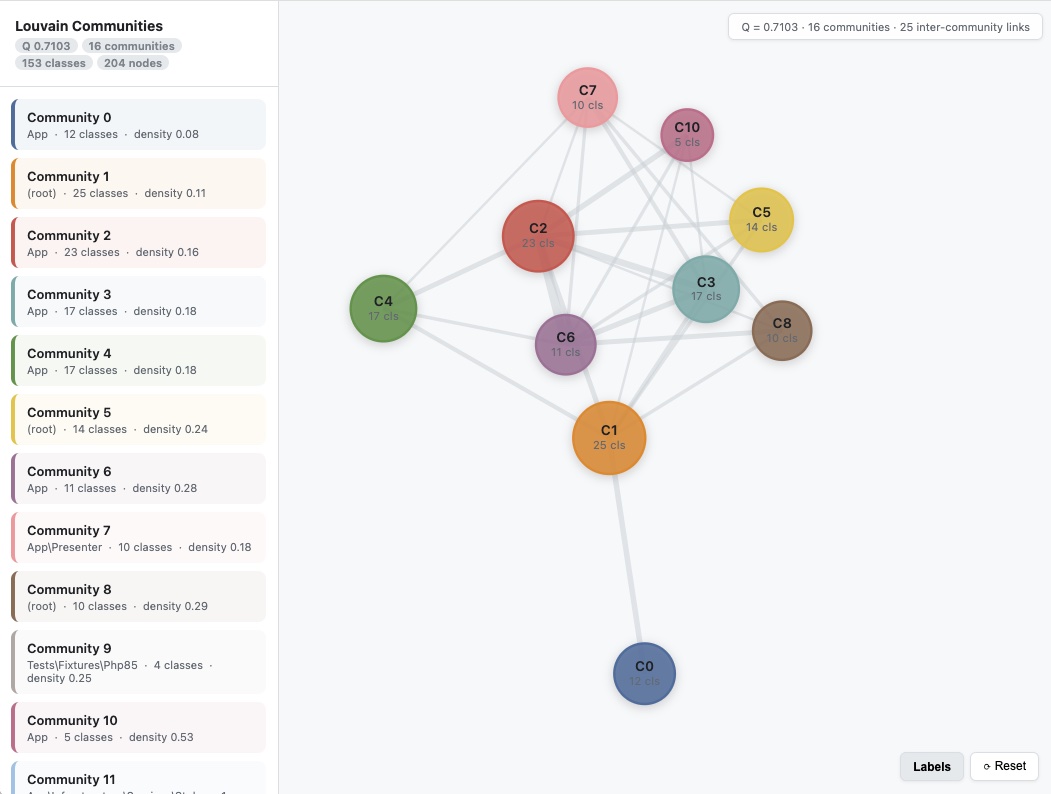 Graphe de communauté obtenu par php-dep-louvain
Graphe de communauté obtenu par php-dep-louvain
L'outil est volontairement minimaliste, prenant en entrée un graphe de dépendances et retournant les communautés détectées.
Pour aller plus loin, ast-metrics propose quant à lui une analyse bien plus complète de l'architecture : métriques de couplage, statistiques sur les dépendances, visualisations avancées.
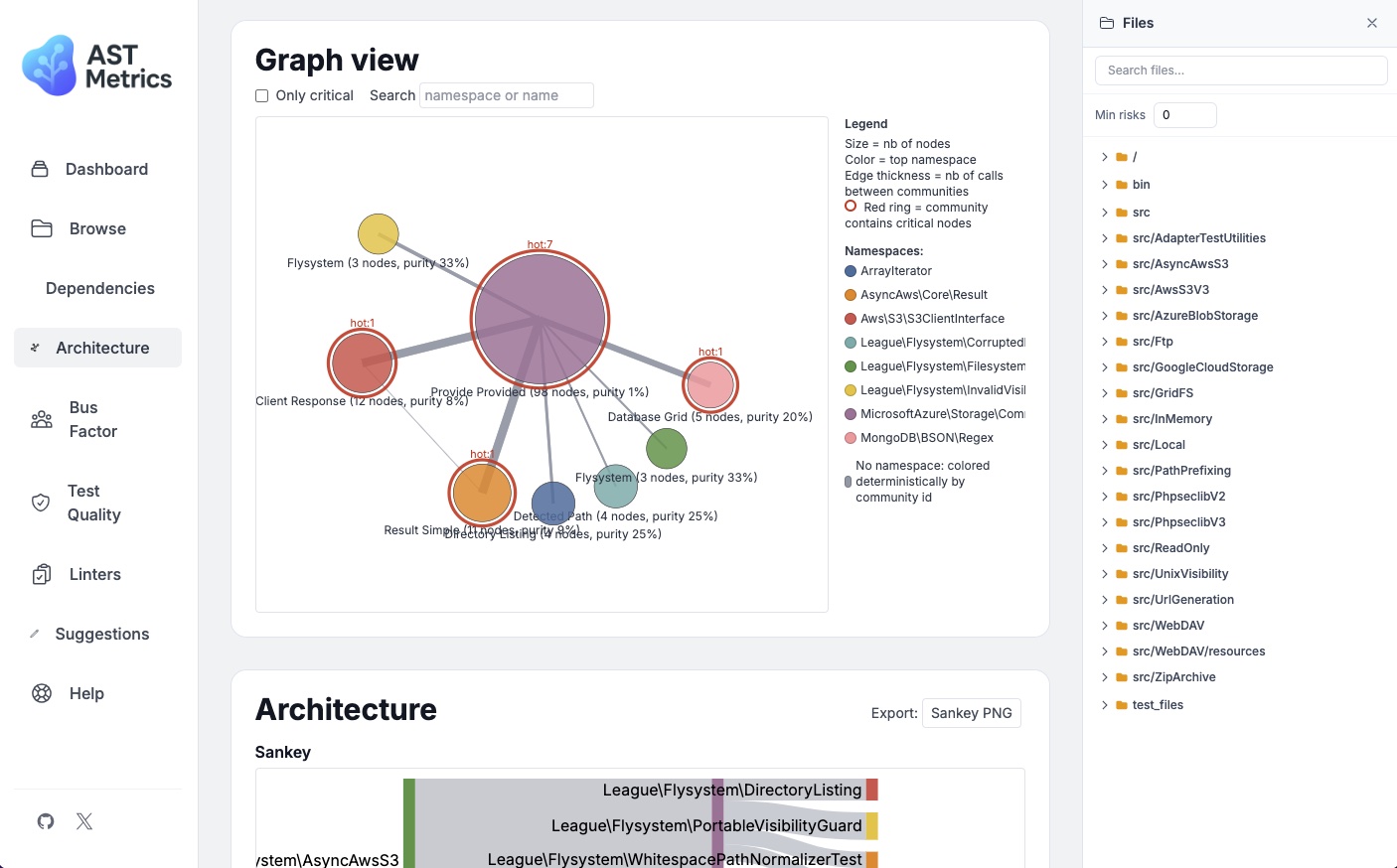 Interface web de ast-metrics
Interface web de ast-metrics
L’outil sera particulièrement utile si vous souhaitez creuser en profondeur l’architecture et obtenir des indicateurs supplémentaires sur la santé de votre application.
Conclusion
L'algorithme de Louvain ne dit pas comment structurer une application, il met seulement en évidence sa structure réelle.
Cette nuance est importante, on a souvent tendance à considérer qu'une architecture bien pensée est immuable, que les frontières posées à un instant T seront respectées dans le temps.
La réalité d'un projet vivant est bien différente : les dépendances s'accumulent, les couplages s'installent discrètement et la cohésion que l'on croit avoir maintenue peut s'éroder sans que personne ne s'en aperçoive vraiment.
Une communauté dense ne reflète pas forcément un module bien conçu, elle reflète un ensemble de classes qui ont accumulé des raisons communes de changer.
Une communauté traversant plusieurs modules que vous pensiez distincts sera alors une preuve évidente d'un couplage involontaire.
Cette analyse peut alors devenir un indicateur de tendance : est-ce que le couplage se concentre ou se diffuse ? Est-ce que les frontières que l'on pensait tenir sont toujours visibles dans le code ?
La détection de communautés ne remplacera pas la réflexion architectural, mais elle permet de la nourrir en apportant une observation concrète là où on n'avait jusqu'ici que des intuitions.
Les communautés ne reflètent pas ce que vous avez voulu construire elles reflètent là où votre code a appris à changer ensemble.

Pour visualiser rapidement les communautés de votre repository GitHub, et analyser par la même occasion votre code, vous pouvez utiliser ce site analyze.ast-metrics.dev !

Je ne connaissais pas du tout alors que c'est vraiment intéressant !
J'ai un nouveau client qui justement a fait développer un gros Laravel par un prestataire externe.
Le code a été livré sans doc et il a besoin que je jette un coup d'oeil là dedans... Ce package me paraît parfait !
Tu veux commenter ? Crée un compte ou connecte-toi.
A lire
Autres articles de la même catégorie

Les bases du CQRS en Laravel
Découvrir les bases de l'architecture CQRS en Laravel.
Mathieu De Gracia

Installer une beta de PHP en CLI
Que ce soit pour tester une nouvelle alpha ou s’amuser sur une vieille version, voyons comment installer en quelques minutes une version spécifique de php en CLI.
Mathieu De Gracia

La méthode Mikado à la rescousse de nos refactos !
Découvrons ensemble la méthode Mikado qui nous aide à refactoriser de manière itérative et logique notre code
 William Suppo
William Suppo