Clean Architecture : conduire le changement au sein d'une équipe

- Vocabulaires
- Les développeurs
- Les choses essentielles
- Une architecture progressive
- Par où commencer
- Accepter des solutions imparfaites
- S'engager à livrer
- Conclusion
Cet article fait suite à celui consacré à la mise en place d’une Clean Architecture dans une application Laravel avec un fort historique.
Le précédent article se concentrait essentiellement sur notre compréhension des architectures en couches, sur les stratégies techniques et les différentes implémentations que nous avons pu mettre en place.
Celui-ci se concentrera sur un autre aspect, bien moins technique, mais tout aussi important : comment, en tant que lead développeur, j’ai embarqué les développeurs de l’équipe dans cette refonte
Il s'adresse à tous ceux qui souhaitent transformer une base de code existante en un terrain d’apprentissage collectif autour de la Clean Architecture.
Vocabulaires
Avant de débuter cet article, il est important de maîtriser quelques termes clés afin d'appréhender plus sereinement les chapitres suivants.
Un composant est une brique fonctionnelle de votre application regroupant un ensemble de classes dédiées à un enjeu précis, qu’il soit technique ou métier : par exemple, la prise de commande, l’onboarding de vos utilisateurs, la gestion des comptes ...
Les composants sont représentés par le schema suivant :

Une classe est une unité de code détenue au sein d’un composant, chaque classe possède une responsabilité précise et contribue à l’objectif global du composant, elles sont représentées par le schéma :

Un composant peut être organisé en plusieurs couches, chaque couche regroupe un ensemble de classes ayant un type de logique particulier, par exemple, la logique de présentation, logique métier, d'infrastructure, etc ...
Chaque couche sera représentée par une couleur spécifique et illustré par le schéma suivant :
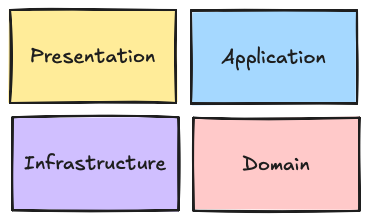
Pour finir, il est important de comprendre le sens des flèches qui peuvent exister entre les composants, les couches et les classes. Chaque flèche représente la dépendance et la connaissance d’un élément envers un autre.
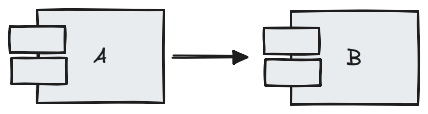
Dans l’exemple ci-dessus, le composant A a connaissance du composant B et en dépend donc. À l’inverse, le composant B n’a pas connaissance du composant A et n'a donc aucune dépendance envers lui.
Les développeurs
Durant toutes ces refontes, vos principaux interlocuteurs seront les développeurs.
Ce sont eux qui vivront l’architecture au quotidien, qui en sentiront la complexité et qui porteront le projet sur leurs épaules, leur adhésion n’est donc pas un luxe mais un point d’ancrage tout simplement indispensable.
Vous ne pourrez jamais rien construire de solide si l’équipe ne marche pas avec vous. Une refonte, un changement de cap, une nouvelle manière de penser ... tout cela demande une implication réelle et non une exécution mécanique.
Votre rôle de Lead commence ici : créer les conditions pour que ces concepts soient compris et intégrés.
Concrètement, cela signifie présenter les idées en groupe puis à prendre le temps d’éclairer individuellement ceux qui auraient besoin de précisions. Produire des supports, des schémas, des analogies ... et recommencer jusqu’à ce que l’ensemble prenne forme dans l’esprit de l’équipe.
Vous allez probablement répéter les mêmes choses, encore et encore, et si des points de blocage subsistent vous serez alors contraint de revoir votre approche différemment.
De par votre rôle de leader, c’est à vous d’assumer la responsabilité de lever les incompréhensions.
Un tableau collaboratif, comme excalidraw, sera alors salvateur pour vous et vos équipes, vous permettant de prendre de la hauteur et de mieux visualiser les concepts et les synergies entre les différentes composants de votre application.
La pédagogie sera le principal levier d'adhésion des développeurs. Attendez-vous à ce que votre tableau blanc se remplisse rapidement de dizaines et dizaines de schémas : griffonné, souvent chaotiques, mais servant de véritables supports de réflexion et de discussion pour les équipes.
Passez un pacte avec les développeurs : vous prendrez toujours le temps de les accompagner à condition qu’ils acceptent de rester ouverts face à leur propre incertitude.
Ne pas comprendre un concept n'a rien d'alarmant, c’est même inévitable, d'autant que les architectures en layers ne sont pas toujours accessibles ou évidentes à appréhender. Ne dites jamais, au grand jamais, que ces choses sont simples, car vous ajouteriez une barrière supplémentaire à leur bonne compréhension : celle du jugement personnel.
Si je ne comprends pas cette chose simple, est-ce que je suis bête ?
Au contraire, embrasser cette complexité, présenter les choses telles qu'elles sont, avec toute leur richesse et leur complexité. Restez sincère dans ce que vous abordez et constituez un environnement de travail sain dans lequel les développeurs pourront exprimer leurs craintes sans peur du jugement.
Gardez en tête que certaines résistances ne sont pas de la mauvaise volonté.
Face à la peur de l’échec, du jugement ou de la surcharge cognitive, il est naturel que certains développeurs cherchent une faille dans la théorie plutôt que d’affronter un terrain qu’ils perçoivent comme déstabilisant : percevez cette situation comme un mécanisme de protection et non un refus d’apprendre.
Cette situation est d’autant plus problématique que vous n’aurez pas toujours réponse à toutes leurs interrogations. Votre propre compréhension de la clean architecture peut encore être partielle ou incomplète et votre incapacité à répondre peut les laisser dans l’incertitude, voire pire, être perçue comme une faiblesse confirmant leurs doutes.
C’est précisément dans ces moments de flottement que votre posture de Lead compte le plus : vous n’avez pas besoin d’avoir réponse à tout pour incarner une direction.
Faites-leur prendre conscience que la Clean Architecture est un concept robuste et éprouvé, cela n’est pas une lubie personnelle, ni une mode passagère, mais une architecture pensée, testée et validée par des développeurs à toutes les échelles.
Cette posture de rejet protège temporairement leur estime de soi, mais pourrait devenir délétère pour le projet et l'équipe car elle freine la progression collective et empêche de dépasser les obstacles techniques.
Si cette situation perdure, deux options s’offrent à vous.
Si le point de friction n’empêche pas la mise en place globale, ne vous attardez pas sur ces points de détails. Concentrez-vous sur l’essentiel et acceptez que le code produit ne soit pas parfaitement conforme à ce que vous aviez imaginé.
Si au contraire le point de blocage est central, invitez alors le développeur à suspendre momentanément son besoin de comprehension et proposez-lui de passer à la pratique, même à l’aveugle.
Il ne s'agit pas d’imposer quoi que ce soit mais simplement d’offrir le temps nécessaire pour que l’idée prenne. Et bien souvent, le blocage se réduira de lui même quand la vision d’ensemble de la Clean Architecture commencera à faire sens et à s'installer naturellement.
Dans tous les cas, pédagogie, bienveillance et confiance doivent rester vos maîtres-mots : à vous de trouver le bon équilibre à adopter.
Les choses essentielles
Bien que les architectures en layers soient complexes, il est toujours possible de les démystifier en résumant ces concepts de manière simpliste, voire naïve.
Avec du recul et le retour d'expérience de plus d'une dizaine d'applications PHP / Laravel en Clean Architecture, j’apprécie désormais de les simplifier à l’extrême avec la phrase suivante : les choses essentielles ne dépendent pas des choses triviales.
« Why is more important than how »
— Second Law of Software Architecture
Cette phrase est volontairement floue et abstraite mais elle reprend à mes yeux l’essence même de la Clean Architecture, ou du moins ce qu’elle cherche à nous transmettre.
Cette relation ne peut cependant aller que dans un sens, une chose importante ne doit jamais dépendre d’une chose moins importante : c’est aussi clair que ça.
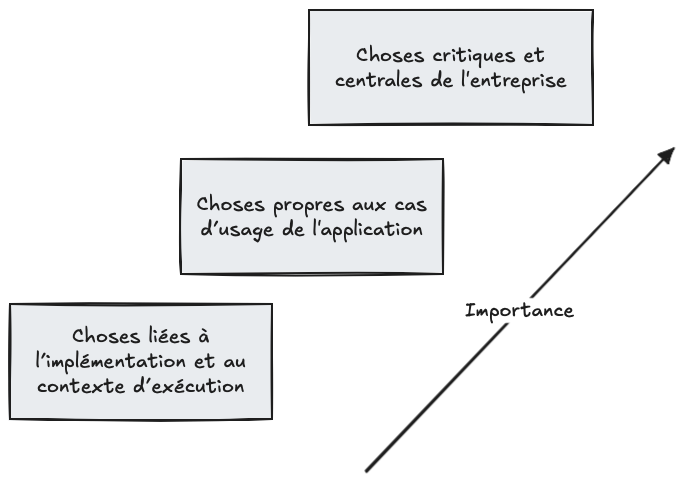
Tentons maintenant de l'illustrer avec un exemple plus concret.
Imaginez la classe portant la logique de facturation, c’est probablement l’un des éléments les plus critiques de votre application, utilisé et réutilisé dans de nombreuses situations.
À ce titre, elle ne devrait en aucun cas connaître les détails insignifiants de l’interface utilisateur. Une telle dépendance la rendrait plus rigide, moins testable, moins réutilisable ... et ferait planer un doute sur sa capacité à évoluer sereinement.
Et pourtant c’est exactement ce qui se passe quand les couches centrales de votre architecture commencent à dépendre de l’interface utilisateur, du framework, d'une API ou tout simplement de la base de données.
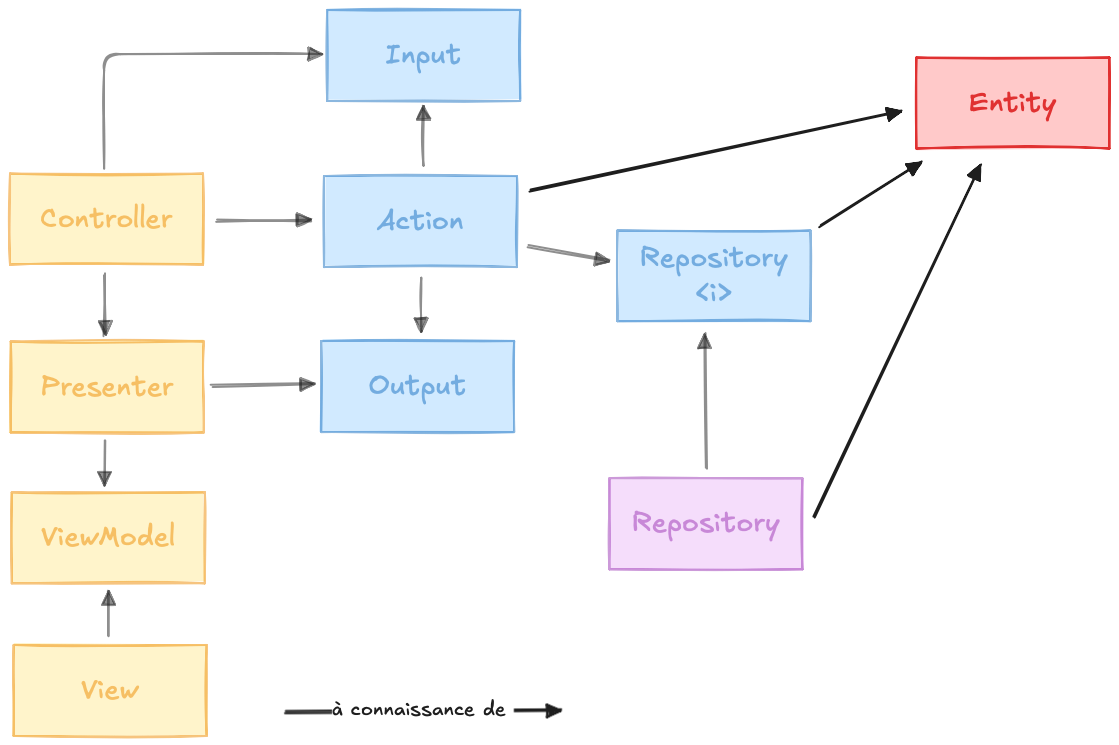
Il est parfois difficile de mettre des mots sur ces "choses" alors la Clean Archi propose habituellement ce fameux découpage en 4 layers :
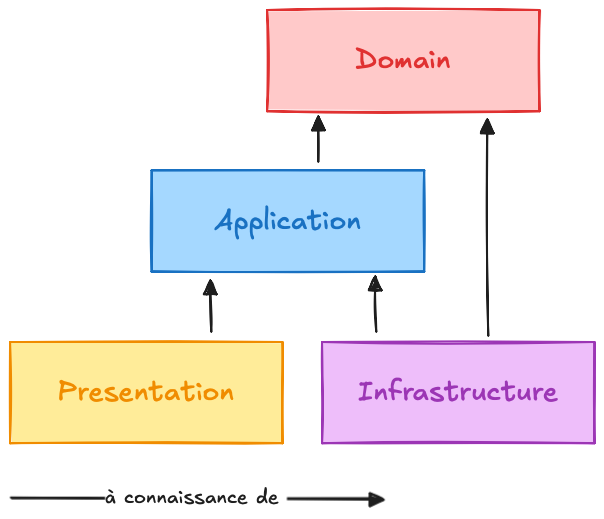
Les choses les plus triviales se trouvent à la base de ce schéma : la logique de présentation et d'infrastructure. La logique applicative s'appuie dessus et sert au bon fonctionnement de la logique métier qui se situe tout en haut du schéma.
Mais ce découpage n’est pas qu’un simple empilement de composants : il vise à isoler ensemble les éléments qui évoluent au même rythme et pour les mêmes raisons.
Ainsi, la couche domaine, qui change peu et uniquement pour des raisons métier, reste indépendante des couches techniques, plus sujettes à des changements fréquents liés aux évolutions technologiques.
Ce regroupement cohérent, et le respect des frontières, permettent de limiter la propagation du changement et de préserver la stabilité du cœur de votre application.
Essayons maintenant de mettre des mots sur ces différentes couches :
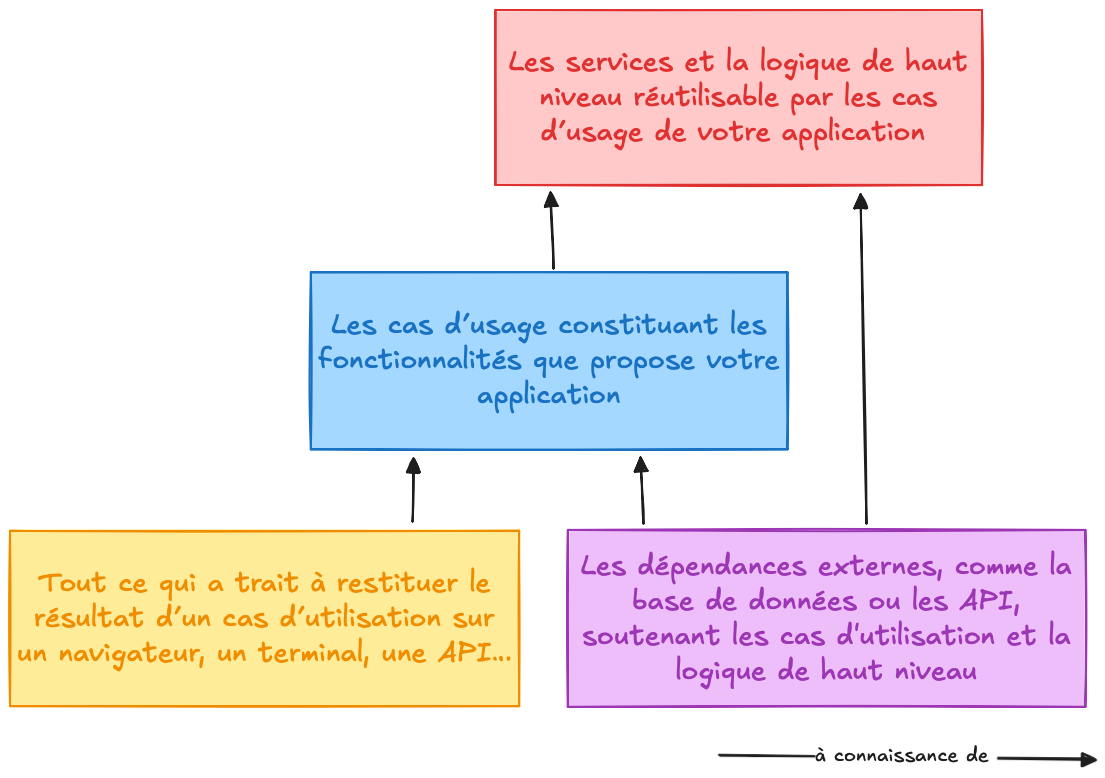
Plus une couche est haute dans ce schéma et plus elle est centrale, stable et précieuse : c’est le cœur de votre métier, ce qui donne un sens à votre application.
Plus nous descendons, plus nous nous approchons du sol et des détails concrets, changeants et remplaçables. Cela ne signifie pas que les couches du bas sont inutiles, elles sont simplement moins fondamentales.
L'interface utilisateur est régulièrement revue, le schéma de la base de données évolue constamment, vos frameworks changent, se mettent à jour, déprécient des fonctionnalités ou en ajoutent de nouvelles ... mais la logique métier, elle, perdure car son inertie est beaucoup plus forte.
Les règles de calcul des taxes de votre entreprise, présentes dans la couche domaine, évolueront ponctuellement tandis que le package permettant d'effectuer des appels API, dans votre couche d'infrastructure, recoit probablement des mises à jour hebdomadaires.
Le découpage proposé par la Clean Architecture met en lumière cette différence : les détails techniques évoluent vite, la logique métier beaucoup plus lentement.
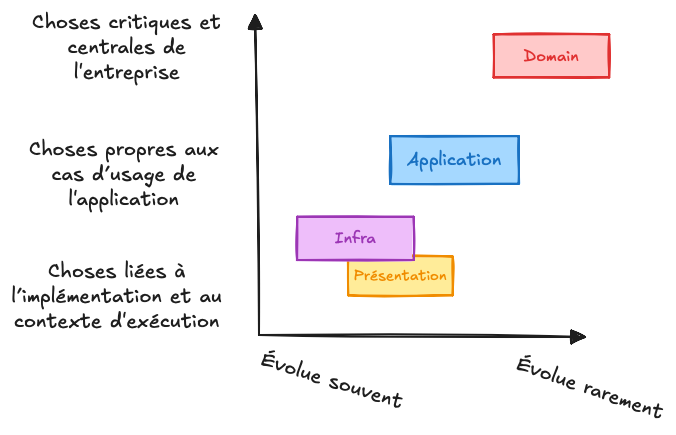
Il est nécessaire de transmettre cette philosophie car plus que des schémas complexes, la Clean Architecture repose sur une idée simple : construire une architecture stable, c’est savoir distinguer ce qui doit durer de ce qui est amené à changer et à organiser le code en conséquence.
« Architecture is about the important stuff. Whatever that is »
— Martin Fowler
Une architecture progressive
Appliquer à la lettre les concepts de la Clean Architecture tels que décrits par Robert C. Martin est une tâche difficile, parfois même inatteignable, lorsque l'on travaille sur un projet avec plusieurs années (voir décennie) d'héritage.
Vous ne pourrez pas tout refactoriser, peut-être car votre couverture de tests n’est pas suffisante pour sécuriser ces travaux. Peut-être que la codebase est trop vaste et le temps trop limité. Ou peut-être tout simplement que votre compréhension, ou celle des développeurs, n’est pas encore assez solide pour envisager une implémentation complète.
En somme, vous êtes confronté au monde réel et à cela, je ne répondrai qu’une seule chose : détendez vous, tout n’a pas besoin d’être parfait.
Aujourd’hui encore, la plupart de nos implémentations restent partielles, car la qualité architecturale doit toujours être en corrélation avec la valeur de ce que l’on développe : tous les développements n’ont pas besoin d’être coûteux pour répondre de maniére adéquates à nos utilisateurs.
Dans ce processus d’apprentissage, il serait vain d’espérer une conformité totale avec la théorie dès la première implémentation, cela est tout simplement impossible, il y a énormément de notion à transmettre, à comprendre, à expérimenter.
Les implémentations seront donc forcément progressives, parfois maladroites, souvent incomplètes … et c’est normal.
Le plus important sera toujours de comprendre les concepts, de bien saisir les règles pour réussir à en capter l’essence et peut-être, avec le temps, apprendre à les détourner.
La Clean Architecture est un ensemble de principes qui s’entremêlent et se complètent : certains concernent la stabilité, d’autres la modularité, d’autres encore les dépendances ou les notions de responsabilités.
Vous n’avez pas besoin de tous les connaître par cœur pour avancer : comprendre les grandes idées, les expérimenter pas à pas, sera un excellent début !
Voyons maintenant la lente progression que nous avons pu observer dans l’implémentation de la Clean Architecture au fil de nos projets.
La couche applicative
Pour commencer, nul besoin de parler directement de Clean Architecture, vous devrez d’abord transmettre des réflexions sur l’isolation des couches et l’action se prêtera très bien à l'exercice.
L'architecture n'est pas qu'un empilement de choses ou une organisation de dossiers, c'est avant tout une réflexion plus globale sur la manière dont les éléments interagissent entre eux et dépendent (ou non) les uns des autres.
Le pattern action est à la mode depuis quelques années, la plupart du temps les développeurs l’utilisent pour encapsuler du code auparavant situé dans les controllers, c’est un bon début mais insuffisant si nous réfléchissons en terme d'architecture.
Ce qui compte vraiment, c’est l’isolation de l’action.
Une action ne doit pas savoir qui l’utilise : un contrôleur, une commande, un job ? Peu importe, tout cela n’est qu’un détail technique, un bruit extérieur qui ne doit jamais influencer son comportement.
Il est donc inacceptable de voir une action dépendre de quoi que ce soit qui trahirait son contexte d’exécution. Par exemple, passer une instance de Request à une action revient à la lier implicitement à un contrôleur HTTP : c’est une transgression du principe même d’isolation.
L’action n’a que faire de ces détails, son rôle est simple : faire une chose, bien, et sans dépendre du monde extérieur.
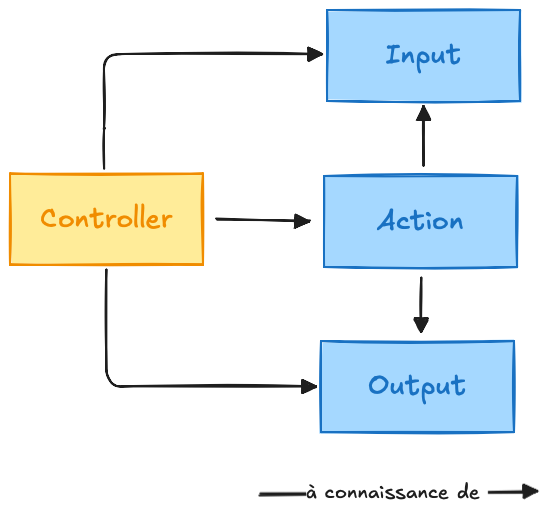
Une action declare donc un besoin, à travers un DTO Input et retourne des informations sous la forme d'un autre DTO, le Output.
Cette première étape sera relativement simple à mettre en place, consistant essentiellement à déplacer du code, mais cela vous permettra d'entamer les premières discussions sur l'isolation des couches et de comment l'information et le contexte d'utilisation peuvent fortement influencer les composants : en somme, vos premières réflexions d'architectures.
La couche de présentation
Maintenant que l'action contient tout le code d'un cas d'utilisation, la logique d'affichage se trouve toujours dans un contrôleur, dégradant sa testabilité, il sera désormais temps d'ajouter un nouveau composant : la logique de présentation.
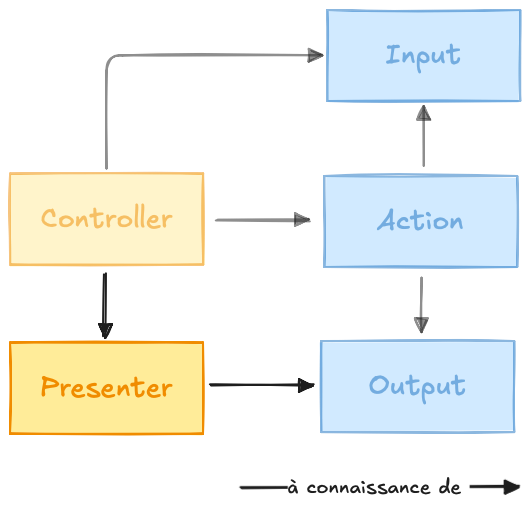
Cette étape consistera surtout à déplacer tout le code ayant trait à la réponse de l'utilisateur : les redirections, les flash messages, préparer les messages d'erreur, afficher les pages, etc
En isolant ces préoccupations dans un composant dédié, vous pourrez les tester de manière exhaustive, en dehors du contrôleur et donc sans la nécessité de simuler une requête HTTP dans vos tests : pouvoir tester comment votre application réagit à l'output d'une action est une chose précieuse que vous apprécierez certainement.
Cette seconde étape ne devrait pas poser d'interrogation supplémentaire, les réflexions étant les mêmes que celles qui vous auront poussé à découper votre action précédemment : regrouper les logiques vivant pour les mêmes raisons et au même rythme et les isoler du monde extérieur
À ce moment là, toute la logique de présentation devrait se trouver dans le Presenter, celui ci reçoit l'output de l'action, prépare les données et les restitue à l'utilisateur.
Pour aller un peu plus loin dans le composant de presentation, vous pourrez mettre en place deux nouveaux composants : un View et un ViewModel.
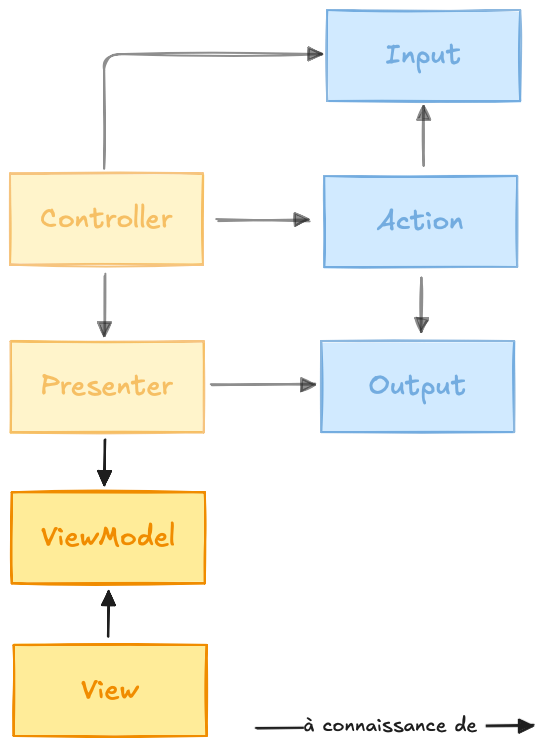
Préparer et restituer sont deux préoccupations différentes, afin de respecter plus finement le principe de responsabilité unique, nous pourrions déplacer ces logiques dans deux nouvelles classes : le ViewModel, un DTO contenant les informations à afficher, et la View, une classe chargée de restituer ces informations à l’utilisateur en manipulant le ViewModel.
Nous obtenons ainsi un triptyque de classe ayant chacune une responsabilité marquée et unique :
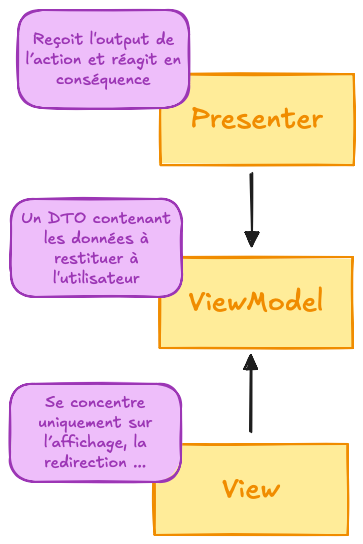
Encore une fois, ces nouveaux composants ne sont qu’une continuité des réflexions initiées avec l’Action et le Presenter et ne devraient pas représenter un défi complexe. D’autant que leur utilisation ne sera ni systématique, ni réellement avantageuse, en dehors des fonctionnalités présentant une certaine richesse de présentation.
La couche d'infrastructure
Nous arrivons désormais à un point de bascule, jusqu’à présent les modifications apportées au code consistaient essentiellement à identifier, et à encapsuler, la logique applicative et de présentation en les isolant des interactions avec le monde extérieur : en particulier celles provenant de l’utilisateur via les points d’entrée de l’application.
Désormais, notre attention doit se porter sur les dépendances de notre Action provenant de l’autre côté de notre schéma : celles qui viennent de l'infrastructure de l’application.
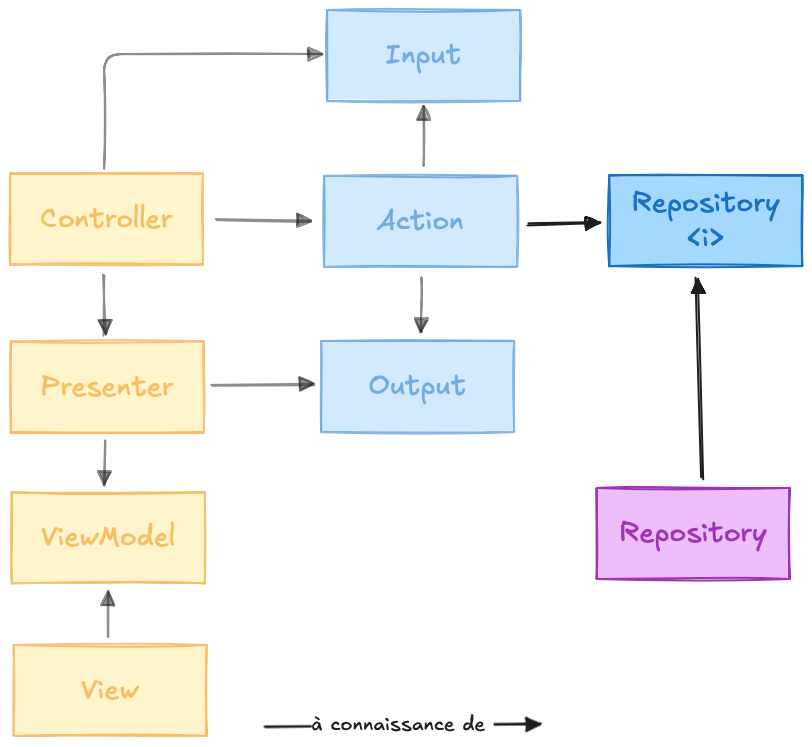
Fondamentalement, les réflexions restent les mêmes : toujours orientées autour du découplage et de la testabilité des composants. Les éléments présents dans la couche infrastructure sont ceux faisant le lien avec la base de données, les API, ou encore le système de fichiers.
Ces contraintes techniques ne doivent en aucun cas influencer le fonctionnement de notre action car ce ne sont que des détails.
Au contraire, il est important de réaffirmer auprès des développeurs que l’action est responsable d’orchestrer la logique métier de l’application, c’est à dire ce que l’application propose concrètement comme fonctionnalités à ses clients.
Par exemple, notre application possède une action destinée à accueillir un nouvel utilisateur. Pour fonctionner, cette action a besoin d’intermédiaires qui délèguent les détails techniques, c’est là que l’infrastructure entre en jeu : l’action déclare ses besoins via des interfaces que la couche d’infrastructure se chargera d’implémenter.
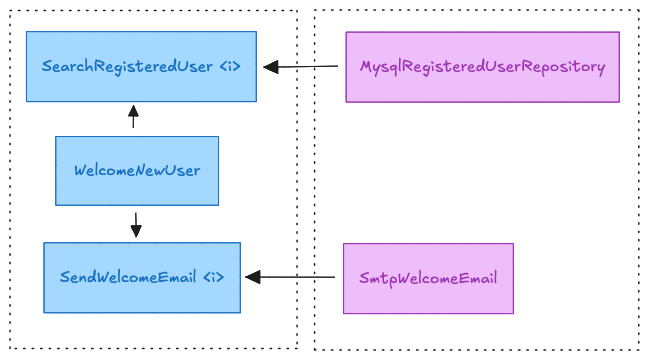
Cette contrainte vous amènera à créer de multiples interfaces pour répondre aux besoins spécifiques de vos actions. Chaque interface sera le fruit d’une réflexion visant à identifier précisément les dépendances fonctionnelles nécessaires au bon déroulement des traitements métier.
Les développeurs pourraient s’étonner de voir des interfaces implémentées par une seule et unique autre classe, comme c’est le cas dans notre schéma ci-dessus : rappeler leur que les interfaces jouent un rôle architectural crucial, bien au delà de simples contrats.
Ces interfaces constituent une indirection essentielle : elles séparent le besoin exprimé par l’action de son implémentation technique concrète.
Cette indirection permet de différer les choix techniques et favorise un découplage fort entre les couches. Ainsi, l’évolution du code reste maîtrisée car les modifications techniques n’impactent pas les couches supérieures de l’application.
Le code contenu dans la couche d’infrastructure est mouvant, souvent très technique et de bas niveau, il est pourtant trivial car décoléré des enjeux métier.
Tout le monde peut écrire des appels HTTP, des requêtes en base de données, manipuler un système de fichiers … Cela n’a aucune valeur intrinsèque pour vos clients. La véritable valeur se trouve dans les couches supérieures (applicative et domaine) car ce sont elles qui incarnent ce que vous vendez réellement.
Par moments, surtout avec du code legacy, il peut être difficile d’identifier clairement ce qui relève de la logique applicative et ce qui appartient à l’infrastructure. Peut-être que le code que vous cherchez à remanier est en réalité un effet de bord d’une implémentation technique ?
Dans ce cas, et pour des raisons de pragmatisme et de simplicité, je vous conseille fortement de simplement déplacer ce code dans la couche d’infrastructure. À moins d’une refonte majeure, il sera en effet coûteux de remanier ces éléments en profondeur.
Arrivé à cette étape, la nature de vos architectures aura déjà considérablement évoluée : les logiques seront bien mieux découplées et leur testabilité grandement facilitée.
Vous pourriez probablement vous arrêter là car l’essentiel aura déjà été transmis, et c’est d’ailleurs ce que je vous conseillerais de faire : laissez les développeurs expérimenter, se tromper, apprendre. C’est ainsi que les notions de découplage s’enracinent durablement.
Ce n’est qu’ensuite que vous pourrez aborder la dernière, et non des moindres, couche : la couche domaine, celle qui contient notamment les entités de votre projet.
La couche Domain
D’expérience, la couche domaine sera la plus complexe à présenter aux développeurs et la plus difficile à introduire dans un projet existant, il y aurait énormément à dire sur cette couche et sur la nature du code qu’elle contient.
Permettez vous d’aborder les choses de manière simpliste : la couche domaine porte la logique métier de plus haut niveau, celle qui caractérise votre entreprise et la rend unique.
« The domain layer code encapsulates the most fundamental and high-level rules of the system »
— Robert C. Martin
Les composants qu’on y trouve contiennent l’intelligence et les règles métier réutilisables par les autres couches : ce sont les composants les plus centraux et critiques de votre projet.
La couche domaine n’a aucune connaissance des couches inférieures : insistez sur le fait que cette indépendance vis-à-vis du monde extérieur rend le code du domaine extrêmement testable.
Il devient facile de créer des entités via des builders, puis de les éprouver à travers de véritables tests unitaires, sans (trop) dépendre du framework, d’une interface utilisateur ou d’une quelconque infrastructure.
Essayons d’illustrer ces notions à l’aide d’un exemple concret : celui d’une prise de commande dans une application de e-commerce.
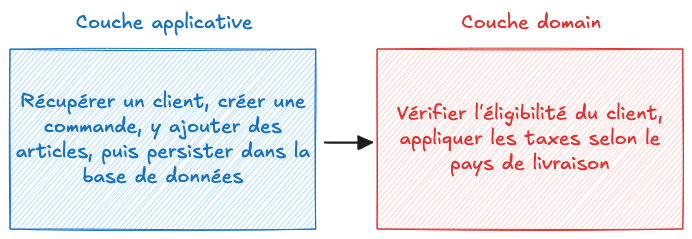
Vous trouverez dans la couche application une action PasserCommande qui orchestre l’ensemble du processus et la communication avec les autres couches.
Mais la logique métier, comme la règle stipulant qu’un client ne peut commander que si son compte est actif, ou la manière de calculer les taxes selon le pays de livraison, se trouve, elle, dans la couche domaine : ces règles sont encapsulées dans des entités ou des services métier car elles sont de plus haut niveau et potentiellement réutilisables par plusieurs actions.
Cependant, tout cela reste abstrait et l’appréciation de la "hauteur" d’une couche est subjective … ce qui explique probablement pourquoi ces enjeux sont si difficiles à transmettre !
Rien n’interdit non plus l’existence de couches encore plus hautes que le domaine, si des logiques stratégiques ou interdomaines le justifient, l’essentiel est ailleurs : il s’agit de toujours respecter le sens des dépendances, ainsi que l’isolation des couches.
Au delà de ces considérations théoriques, on peut se poser une question simple : pourquoi l’ajout d’une couche domaine est il si difficile dans un projet avec un fort héritage ?
La réponse pourrait tenir en un seul mot : le couplage.
Malgré les efforts nécessaires, l’introduction des premières couches (Presenter, Applicative et Infrastructure) se fait relativement naturellement : il s’agit avant tout de déplacer du code existant, de clarifier les intentions et de poser des frontières dans un code déjà en place.
Même les nouvelles interfaces, parfois verbeuses, obéissent à une logique utilitaire simple : elles matérialisant un besoin déjà exprimé par l’action et leur extraction améliore le découplage et la testabilité sans bouleverser l’existant.
Mais introduire une couche domaine est une histoire bien plus complexe.
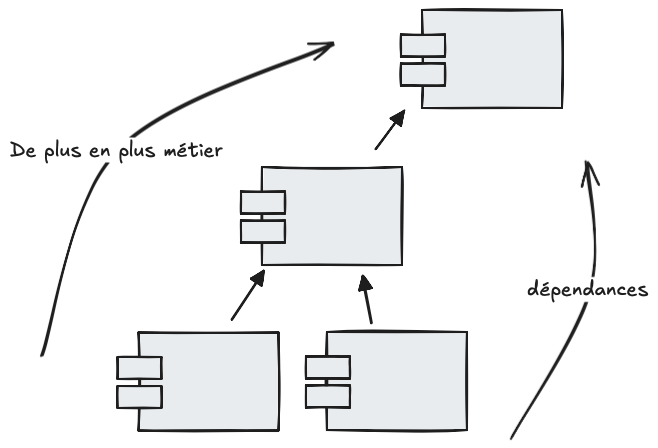
Contrairement aux autres couches, le domaine ne se résume pas à une simple réorganisation du code, il ne s’agit plus seulement de déplacer des lignes ou de regrouper des préoccupations similaires : il faut identifier une logique qui, bien souvent, n’a jamais été explicitement formulée.
Une logique métier qui se retrouve malgré elle un peu partout, mélangée à toutes les autres, et qui se révèle difficile à identifier et à extraire :
 Toutes les logiques mélangées au sein d'un découpage purement technique des fonctionnalités ... les prémisses idéales d'une architecture spaghetti
Toutes les logiques mélangées au sein d'un découpage purement technique des fonctionnalités ... les prémisses idéales d'une architecture spaghetti
L’architecture, dans son rôle fondamentale, organise les interactions à travers des règles strictes de dépendances permettant d’identifier et d’isoler les logiques et les fonctionnalités les unes des autres.
Sans cet effort, ces logiques se retrouvent entremêlées au sein des mêmes classes ... rendant toute réflexion architecturale laborieuse et rigidifiant le système.
Dans ce contexte, introduire une couche domaine revient à extraire des idées claires d’un enchevêtrement de responsabilités souvent implicites et à reconstruire une séparation qui, en réalité, n’a jamais vraiment existé.
Le couplage qui est omniprésent, et souvent invisible, génère une dette technique et une forte ridigité difficile à résorber freinant toute tentative d'évolution.
Au final, ce n’est pas tant l’ajout de la couche domaine qui est difficile mais le fait de devoir d’abord démêler ce qui n’a jamais été véritablement structuré.
Par où commencer
Contrairement à ce que l'on pourrait imaginer, les premières étapes d’une implémentation en Clean Architecture ne commencent pas nécessairement par un découpage en couches.
Cela peut paraître surprenant, d’autant que cette architecture semble intrinsèquement liée a ce découpage et que les recherches sur internet renvoient presque systématiquement aux fameux schémas en quatre layers.
Pourtant, selon Robert C. Martin, le vrai point de départ n’est pas le découpage en couches mais la gestion des dépendances et la réutilisabilité des classes, en appliquant le principe CRP (Common Reuse Principle).
Le CRP consiste à regrouper les classes qui évoluent ensemble et répondent aux mêmes besoins fonctionnels. Autrement dit : si deux classes évoluent de concert, elles devraient coexister dans le même composant.
En comparaison, Laravel propose par défaut une organisation centrée sur les aspects techniques : les services d'un côté, les modèles de l'autre. Une organisation pratique pour le framework mais qui n’a rien d’un découpage fonctionnel et qui, sans le vouloir, nous éloigne déjà du CRP.
Appliquer le CRP est particulièrement naturel pour les nouvelles fonctionnalités : il suffit, en pratique, de tout placer au même endroit !
Cela peut sembler contradictoire avec l’idée même d’architecture, pourtant, ce regroupement constituera la base idéale d’un découpage ultérieur plus fin et robuste.
En appliquant le CRP, vous obtiendriez immédiatement un composant structuré, cohérent et cohésif, sans avoir à décider prématurément des couches nécessaires au bon fonctionnement de la fonctionnalité. Ce principe empêche d’empiler le code dans des couches artificielles dont les dépendances restent encore instables ou mal conçues.
Prenons l’exemple d’une nouvelle fonctionnalité à développer : nous pourrions être tentés d’imaginer sans attendre une architecture complexe avec plusieurs couches, des abstractions et des indirections soigneusement choisies.
Cela pourrait fonctionner, selon votre niveau de compréhension de la problématique et votre expérience en architecture. Mais il y a aussi une probabilité non négligeable que le besoin soit encore flou ou mal défini et que l’identification de ces différentes couches reste trop préliminaire, voire bancale.
C’est précisément là que le CRP intervient, en proposant de regrouper, tout simplement, dans un même composant l’ensemble des classes liées à la nouvelle fonctionnalité :
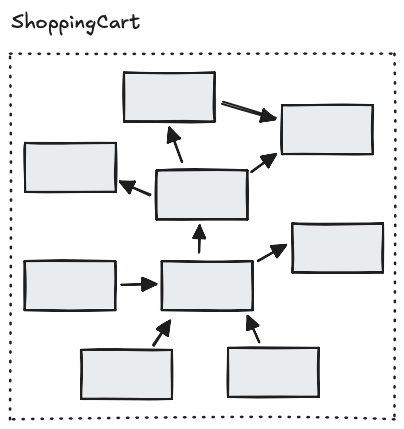
À ce niveau de découpage, concentrez-vous sur deux points : éliminer les cycles entre les classes et éviter les relations bidirectionnelles. Ce n’est pas rédhibitoire au départ, mais ignorer ces contraintes pourrait compliquer l’évolution vers un découpage plus fin en couches.
Le CRP remet à plus tard l’identification des couches au sein d’une feature : vous pouvez regrouper toutes les classes liées à un même besoin fonctionnel dans un seul composant, sans vous soucier pour l’instant de leur organisation interne.
En revanche, à l’échelle macro, entre les features elles mêmes, certaines contraintes restent indispensables : aucune relation bidirectionnelle et aucun cycle entre composants.
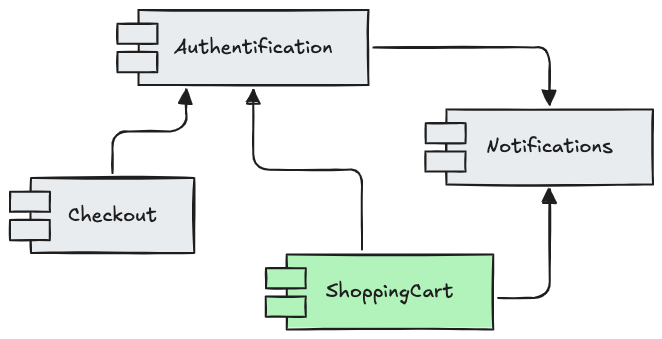
Ces règles assurent que vos features restent indépendantes et évolutives, et constituent la principale contrainte à laquelle le CRP doit se plier.
Une fois la feature stable, testée et répondant efficacement à un besoin, vous pourrez vous pencher sur son découpage interne en identifiant les différents types de logiques qu’elle contient afin de les encapsuler dans des couches dédiées :
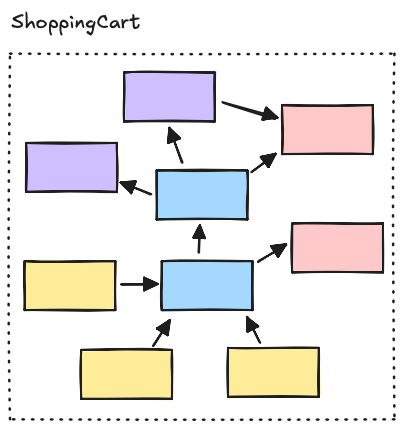
L’identification de ces layers devient naturelle dès lors que les classes sont peu couplées et respectent les principes du CRP.
Vous pourrez également ajouter des abstractions supplémentaires si certaines dépendances paraissent mal orientées et vous assurer que les dépendances vont toujours des éléments techniques vers le métier
Si une telle dépendance problématique existe, vous pourrez facilement la corriger en créant toutes les interfaces et classes supplémentaires afin d'inverser le flux dans le sens que vous souhaitez :

Le CRP constitue une excellente première étape pour toutes vos réflexions d’architecture car il rappelle une vérité essentielle : l’architecture doit d’abord répondre aux contraintes fonctionnelles et non l’inverse.
Tant que le périmètre fonctionnel et technique n’est pas clair, se lancer dans un découpage sophistiqué sera prendre le risque de concevoir une solution inadaptée à un besoin encore flou ou mal maitrisé.
En suivant le CRP, vous limiterez ce risque : en regroupant les classes autour d’une fonctionnalité et en appliquant quelques règles simples sur les dépendances.
Progressivement, les couches se révéleront d’elles mêmes, vous verrez alors apparaître une structure qui, cette fois ci, reposera sur quelque chose de réel et de tangible.
« Make it work, make it right »
— Kent Beck
Accepter des solutions imparfaites
De par sa nature structurante et essentielle, l'architecture semble être indissociable d'un haut besoin de qualité, il serait mentir d'affirmer le contraire mais essayons tout de même de prendre un peu de recul par rapport à la situation.
Tout n’a pas besoin d’être parfait, la qualité architecturale doit toujours être mise en correlation avec la richesse fonctionnelle. Les architectures en layers facilitent l’évolutivité et la testabilité du code … mais ces enjeux ne sont pas toujours présents dans chacun de vos développements.
« Everything in software architecture is a trade-off »
— First Law of Software Architecture
L’implémentation progressive décrite plus haut en est un bon exemple : vous auriez pu vous arrêter à n’importe quelle étape sans avoir honte de vous, même incomplet, ce découpage apporte déjà un gain en robustesse.
Parfois, un simple découpage en CRP suffit à poser des bases solides pour le futur, sans nécessiter un raffinement plus complexe. L’essentiel est de comprendre les enjeux propres à chaque développement puis d’y répondre par l’architecture adéquate.
Appliquez vous à résoudre de véritables problèmes dans vos travaux d'architecture sans vous embarquer dans des refactorisations purement cosmétiques.
La conception d'une application ne consiste pas à mémoriser des patterns et des solutions toutes faites mais à développer une approche plus structurée de la résolution des problèmes. Cette approche, plus itérative, participera naturellement à une amélioration de vos projets et à une montée en compétence graduelle des équipes.
Évitez à tout prix de rester bloqué dans une approche purement théorique, paralysé par la peur de l’erreur, lancez-vous : faire des erreurs, c’est être en capacité d'apprendre de nouvelles choses.
En tant que lead, votre rôle n’est pas d’empêcher toute faute, mais de surveiller leur inertie : ce problème risque-t-il de créer une dette difficile à résorber ? Si la réponse est non, alors laissez les développeurs expérimenter, prendre des initiatives et être acteurs de leurs propres erreurs.
L’exercice sera bien plus formateur pour eux et pour l’équipe s’ils peuvent tester leurs propres idées plutôt que suivre un plan tout tracé.
Contentez-vous d’apporter les notions essentielles et des éléments de langage qui feront naître de nouvelles réflexions et de nouvelles manières d’imaginer l’architecture des projets.
« Continuous improvement is better than delayed perfection »
— Mark Twain
S'engager à livrer
Le rôle d'une équipe reste de livrer des fonctionnalités, l'architecture n'est pas une fin en soi, elle doit toujours rester au service de vos utilisateurs finaux.
Fondamentalement, votre client n'a que faire de la manière dont vous structurez votre code, il ne vous paie pas pour des abstractions élégantes mais pour une application qui fonctionne, qui évolue et qui répond à ses problèmes.
La qualité est certes l'une de nos responsabilités mais elle ne doit pas devenir une excuse pour bloquer la livraison.
Toutes les réflexions présentes dans ces deux articles prendront du temps, c'est inévitable, que ce soit le vôtre, mais également celui des développeurs.
Soyez attentif au temps consommé et veillez à ce qu’il ne dépasse jamais un certain pourcentage du temps alloué à une tâche. Cette contrainte vous poussera constamment à faire des choix, à mettre en production des implémentations partielles et à accepter, de temps à autre, de prendre des libertés avec la théorie.
Il est vital pour une équipe de rester pragmatique et de ne pas s’enfermer dans de longs tunnels de refactorisation dont le succès n’est jamais garanti.
Concentrez vous plutôt sur la livraison de fonctionnalités qui pourront ensuite être enrichies au fil du temps, plutôt que de viser une perfection théorique qui ne verra jamais la production.
Cette équation n’est pas binaire, ce qui la rend particulièrement complexe : la qualité architecturale est indispensable pour permettre à l’application d’évoluer sereinement mais une surqualité peut rallonger les délais et générer des coûts que l’équipe ne pourra pas toujours absorber.
En pratique, tous les développements n’ont pas besoin du même niveau de raffinement : il faut savoir adapter l’architecture à l’importance et à la criticité de chaque fonctionnalité.
« Interesting problems never come with simple answers »
— Martin Fowler
La capacité à livrer d'une équipe doit donc rester un engagement collectif.
Profitez des code reviews pour partager de nouvelles pratiques mais restez vigilants sur les sujets abordés, les code reviews servent avant tout à identifier les défauts et non à réécrire toute l’architecture d’un projet.
À ce stade, remettre en cause des choix structurants est déjà trop tard : relancer un cycle de développement coûte cher, ralentit les livraisons et finit par générer de la frustration.
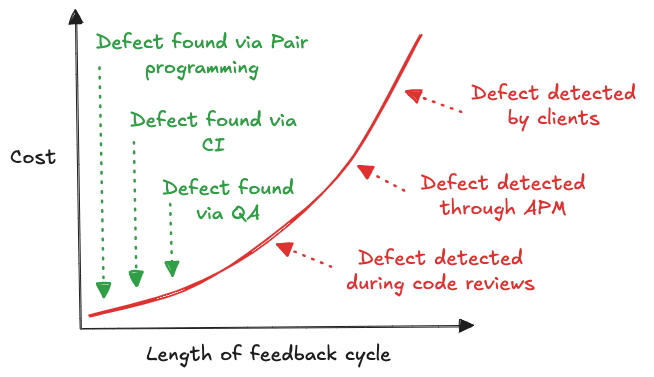
Favoriser toutes prises de décisions importantes en amont du code, à travers les ADR, du pair programming ou encore des ateliers de conception, ces moments permettront d’aligner l’équipe sur les choix techniques, de partager la compréhension des enjeux et d'expérimenter de nouvelles pratiques.
L'architecture n'est pas un chantier ponctuel que l'on planifie à part de la roadmap, c'est une pratique continue et incrémentale qui s'intègre à chaque développement.
Elle se construit pas à pas, dans chaque refactoring, dans chaque nouvelle features, sans jamais perdre de vue l’objectif principal : délivrer de la valeur.
Votre responsabilité est donc double : protéger la qualité du code sans en faire un objectif absolu et garantir la livraison régulière de valeur à vos utilisateurs.
C’est dans cet équilibre compliqué que se jouera réellement la réussite d’un projet et de vos travaux d'architecture.
Conclusion
La mise en place d’une Clean Architecture dans une application n’est ni rapide ni linéaire : elle demande beaucoup de patience, de pédagogie et de pragmatisme.
En tant que lead, votre rôle dépasse la simple technique : il consiste à guider les développeurs, à accepter l’imperfection et à faire évoluer l’architecture pas à pas, tout en maintenant la livraison de valeur pour vos utilisateurs.
À vous de trouver cet équilibre entre protéger la qualité du code, sans chercher une perfection théorique, favoriser l’apprentissage progressif de l’équipe et structurer l’application autour de ses logiques les plus essentielles.
Les couches, les interfaces et les abstractions sont des moyens et non des fins en soit, l’objectif final reste simple : construire un code robuste, évolutif et testable.
Souvenez-vous : l’architecture est un long chemin plein d'incertitude et non une destination.
Chaque refactorisation, chaque nouvelle fonctionnalité, chaque erreur comprise et corrigée contribue à faire grandir votre code et votre équipe.
Avancez pas à pas, restez curieux et bienveillant : c’est ainsi que votre architecture et votre équipe grandiront ensemble.

Écrit par
Mathieu De GraciaLead & Software Architect • nublar.dev
Tu veux commenter ? Crée un compte ou connecte-toi.
A lire
Autres articles de la même catégorie
Clean Architecture : conduire le changement au sein d'une équipe
Retour d’expérience sur la transformation d’une application en terrain d’apprentissage collectif autour de la Clean Architecture : enjeux, difficultés et enseignements.
Mathieu De Gracia

Au-delà du MVC
Réfléchissons à notre relation envers les frameworks et au choix d'architecture qui en découle.
Mathieu De Gracia

Comité Refactorisation : Améliorer le code existant
Résorbez progressivement la dette technique de votre application grâce à un comité de refactorisation
Mathieu De Gracia