Trois dérives architecturales observées en codant avec l’IA

Profitant des long weekends de mai, je me suis lancé dans un petit projet personnel, une application Laravel pour gérer ma collection de jeux vidéo, intégralement générée par IA avec Claude Code 🌸
Cette application était surtout l'occasion d'expérimenter avec différents outils dans un cadre sans contrainte : OCR pour reconnaître les jaquettes, vectorisation pour faire émerger les similarités entre jeux, agents avec function calling pour automatiser certaines tâches.
Rapidement, au fil des développements avec l'IA, plusieurs problématiques d'architecture sont apparues.
Trois dérives en particulier m'ont fait revenir sur des principes que je considérais comme acquis par Claude : le DRY, l'inversion de dépendance, la séparation des responsabilités.
Cet article est le récit de cette journée et de la réflexion qu'elle a déclenchée : nos principes architecturaux sont-ils des vérités intemporelles ou simplement des béquilles à nos limites humaines ?
- Un service, deux contextes
- L'illusion de la duplication maintenue
- La fusion qui empire les choses
- Le couplage par les structures de retour
- Mieux guider l'IA, à quel prix ?
- Et si certains principes devenaient obsolètes ?
- Conclusion
Un service, deux contextes
L'application Laravel possède une page permettant d'ajouter un jeu à une collection.
Le principe est relativement simple : on prend une photo de la jaquette et un service se charge d'en extraire le nom, la plateforme et d'en déduire plusieurs informations.
Voici à quoi ressemblait la première implémentation générée par Claude :
1namespace App\Services; 2 3class GameDetectorService 4{ 5 public function __construct( 6 private OcrClient $ocrClient, 7 private GameMatcher $gameMatcher, 8 ) {} 9 10 public function detect(UploadedFile $image): array11 {12 $rawText = $this->ocrClient->extractText($image);13 14 return $this->gameMatcher->match($rawText);15 }16}Rien à redire, le service est concis, ses dépendances sont injectées, sa responsabilité est claire. Le controller web l'utilise sans probleme, l'application fonctionne, je peux passer à autre chose.
Quelques heures plus tard, j'ajoute un nouveau besoin : pouvoir importer en lot un dossier entier de jaquettes via une commande Artisan, pratique pour numériser toute la bibliothèque quand on possède beaucoup de jeux !
Je formule ma demande à Claude, le code arrive, la commande fonctionne ... et c'est en parcourant les fichiers générés que je découvre une surprise.
Un second service, presque identique, a été créé dans un autre namespace :
1namespace App\Console\Services; 2 3class GameDetectorService 4{ 5 public function __construct( 6 private OcrClient $ocrClient, 7 private GameMatcher $gameMatcher, 8 ) {} 9 10 public function detect(string $imagePath): array11 {12 $rawText = $this->ocrClient->extractText($imagePath);13 14 return $this->gameMatcher->match($rawText);15 }16}À part le type du paramètre d'entrée (UploadedFile côté web vs string côté commande Artisan), les deux classes sont strictement équivalentes : même logique, même dépendances, même finalité fonctionnelle.
Pris isolément, chaque service est correct, leur coexistence n'est visible nulle part, elle n'existe qu'à l'échelle du système, pas à l'échelle du fichier.
L'illusion de la duplication maintenue
Pendant plusieurs itérations, j'ai laissé ce problème de côté, le code fonctionnait et il y avait toujours plus important à traiter.
À chaque évolution fonctionnelle, je formulais ma demande à Claude et le code des deux services était systématiquement modifié de manière cohérente.
J'ajoute un fallback en cas d'OCR raté, les deux services le reçoivent, j'introduis une normalisation des titres, les deux services la reçoivent ... la duplication existait mais la cohérence générale du systeme était maintenue.
Nous pourrions nous demander si la cohérence est préservée, le problème est il vraiment réel ?
À ce stade probablement que non ... et c'est exactement ce qui rend cette situation insidieuse. Un humain ne pourra jamais maintenir deux copies en parallèle très longtemps, sa charge mentale limitée l'aurait poussé à factoriser bien plus tôt, presque par instinct.
L'IA, elle, n'a pas cette contrainte, elle peut tenir dix copies cohérentes du même code sans broncher parce que le coût mental d'une duplication est nul pour elle. Le fameux principe DRY n'est pas un principe qu'elle systématise, c'est un principe qu'on doit lui imposer quand cela est nécessaire.
Puis, au détour d'une itération un peu plus complexe, le drift est apparu.
J'avais demandé à Claude de corriger un bug dans la détection de la plateforme : certaines jaquettes mentionnant à la fois "PS4" et "PS5". La correction a bien été appliquée ... mais uniquement dans le service côté web, Le service côté Artisan est resté avec l'ancienne logique.
Pendant plusieurs minutes mes imports en lot ont produit des résultats subtilement différents de ceux de la page web.
Le bug n'était pas spectaculaire, juste assez discret pour ne pas être remarqué immédiatement et juste assez problématique pour fausser les résultats de ma collection.
La fusion qui empire les choses
Une fois le drift identifié, j'ai signalé la duplication à Claude, sa réponse a été immédiate et techniquement correcte : il a fusionné les deux services en un seul ... sauf que cette fusion a été faite à coups de conditionnels :
1namespace App\Services; 2 3class GameDetectorService 4{ 5 public function __construct( 6 private OcrClient $ocrClient, 7 private GameMatcher $gameMatcher, 8 ) {} 9 10 public function detect(mixed $image, string $context): array11 {12 if ($context === 'web') {13 $rawText = $this->ocrClient->extractText($image);14 // ... logique spécifique au controller15 }16 17 if ($context === 'artisan') {18 $rawText = $this->ocrClient->extractFromPath($image);19 // ... logique spécifique à la commande20 $this->logger->info('Detection from CLI');21 }22 23 return $this->gameMatcher->match($rawText);24 }25}Le code compile, les tests passent, la duplication a disparu mais notre problème vient simplement de changer de nature !
La nouvelle classe accumule désormais deux types de responsabilités très différentes : la détection du jeu et la gestion des spécificités de chaque contexte d'appel.
Pour un seul contexte supplémentaire (par exemple un endpoint API), il faudra ajouter une nouvelle condition puis une autre, puis encore une autre ... la classe ne fait que grossir, et chaque ajout fragilise un peu plus l'ensemble et transgresse le Open/Close du principe SOLID.
Cette situation est également propice à générer un shotgun surgery : un changement mineur dans un contexte risque de provoquer des régressions dans les autres, simplement parce que tous les chemins d'exécution traversent désormais la même méthode.
Mais le vrai problème est peut-être plus profond et plus structurel : l'inversion de dépendance est rompue.
Le service GameDetectorService est censé être un service de domaine dont l'unique responsabilité est de transformer une image en un jeu identifié.
Il devrait totalement ignorer qui l'appelle, cependant, en intégrant le paramètre $context, ce service de haut niveau devient dépendant d'un détail d'utilisation.
Le domaine connaît désormais ses appelants ce qui est exactement l'inverse de ce que prescrit toute architecture en layers correctement pensée.
Il a fallu reprendre la fusion à la main et imposer à Claude ce qu'il avait ignoré : un service unique, agnostique de son contexte d'appel, recevant directement les bonnes abstractions par injection.
Le code a finalement ressemblé à ceci :
1namespace App\Services; 2 3class GameDetectorService 4{ 5 public function __construct( 6 private OcrClient $ocrClient, 7 private GameMatcher $gameMatcher, 8 ) {} 9 10 public function detect(GameImage $image): array11 {12 $rawText = $this->ocrClient->extractText($image);13 14 return $this->gameMatcher->match($rawText);15 }16}Une seule méthode, un seul type d'entrée, aucune connaissance du contexte d'appel, les responsabilités spécifiques à chaque contexte (récupérer un fichier uploadé, lire un fichier sur disque, logger l'opération) sont remontées chez l'appelant là où elles appartiennent.
Pourquoi cette dérive a-t-elle été possible ?
Si le GameDetectorService avait vécu derrière une frontière de domaine clairement définie, exposant un contrat explicite, ni la duplication initiale ni la fusion bloated n'auraient simplement pu exister : Claude aurait été forcé de réutiliser le service parce que le contrat l'aurait imposé
L'architecture en couches ne sert pas qu'à organiser le code, elle agit comme un filet de sécurité qui circonscrit l'action de l'IA et nous permet de lui déléguer la production du code sans perte de contrôle.
Le couplage par les structures de retour
J'aurais pu en rester là, satisfait d'avoir repris le contrôle sur la structure du service.
Pour autant, en parcourant le code une nouvelle fois, un troisième problème est apparu, plus discret encore que les précédents.
Mon OcrClient repose sur AWS Rekognition pour analyser l'image et extraire le texte de la jaquette.
Le service retournait alors un tableau associatif dont la forme reflétait directement la réponse de l'API d'AWS :
1return [2 'title' => 'The Last of Us Part II',3 'platform' => 'PS4',4 'rekognition_confidence' => 87.4,5 'detected_text_blocks' => [...],6 'aws_request_id' => 'a1b2c3d4-...',7 'matched_at' => '2025-11-12T14:23:00+00:00',8];Cette structure est apparue par elle même dans le code généré, parce qu'elle reflète exactement ce qu'AWS Rekognition retourne en interne, légèrement enrichie par la logique de matching.
Chaque appelant de notre service doit désormais connaître la forme exacte de ce tableau pour en extraire ce dont il a besoin.
Le contrôleur web accède à $result['title'], la commande Artisan fait pareil, et toutes les vues qui consomment cette donnée s'appuient sur cette même structure de données.
Cette structure n'a pourtant jamais été conçue comme un contrat : c'est la forme brute de la réponse d'AWS, simplement remontée jusqu'aux appelants sans transformation.
Cette situation est problématique car tout le système s'est progressivement adapté à un format qui n'aurait jamais dû quitter le client OCR.
Chaque appelant repose sur elle, et la moindre modification de cette structure aurait un effet en cascade sur l'ensemble de l'application.
En parallèle, des champs purement techniques comme aws_request_id ou detected_text_blocks traversent toutes les couches jusqu'aux vues, alors qu'ils n'ont aucune raison d'exister en dehors du client OCR.
Malgré nous, le code se rigidifie devant nos yeux : le système devient progressivement dépendant d'un "comment", la forme d'une donnée issue d'une implémentation, au lieu de dépendre d'un "pourquoi", le besoin fonctionnel qu'il était censé servir :
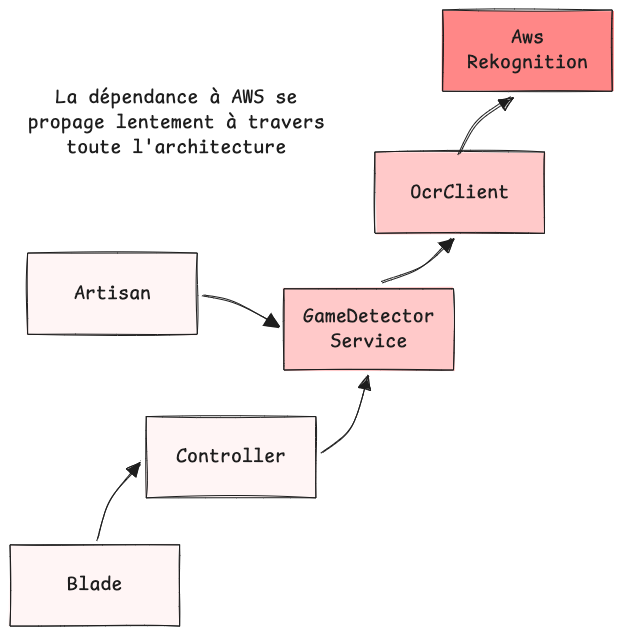
Le jour où je voudrai changer de provider OCR, passer à Google Vision, à Tesseract, ou simplement à un mock pour mes tests, c'est l'ensemble des appelants qu'il faudra alors modifier : le choix d'AWS, qui aurait dû rester un détail d'infrastructure s'est silencieusement diffusé dans toute l'application.
J'ai donc demandé à Claude de remplacer ce tableau par un objet de retour :
1namespace App\Domain\Game; 2 3final class Game 4{ 5 public function __construct( 6 public readonly string $title, 7 public readonly Platform $platform, 8 public readonly Confidence $confidence, 9 ) {}10}L'API publique du service devient alors bien plus stable et explicite, indépendante de la manière dont la détection est réalisée en interne.
Le service peut désormais évoluer librement (changer de provider, ajouter du cache, paralléliser les appels) sans qu'aucun appelant ne soit directement impacté.
C'est exactement le rôle que doit jouer une frontière dans une architecture : isoler les détails d'implémentation derrière des contrats stables pour que le changement reste circonscrit à un périmètre limité.
L'IA, elle, ne voit pas spontanément cette frontière : elle voit une fonction qui prend une image et retourne des données.
Le tableau associatif est la solution la plus économique pour elle pour atteindre ce résultat et rien dans son contexte ne lui suggère que ce choix produira de la dette technique trois mois plus tard.
Mieux guider l'IA, à quel prix ?
Tout ce que je viens de décrire pourrait laisser penser que l'IA est livrée à elle même, c'est évidemment faux.
Les CLAUDE.md, les skills, les guidelines ... ces mécanismes permettent d'imposer des conventions, des patterns ou des frontières architecturales en amont de la génération.
Si j'avais correctement formalisé la structure attendue de retour de mon GameDetectorService dans un CLAUDE.md, Claude aurait probablement créé l'objet Game dès la première itération.
Si j'avais imposé une convention de nommage et de localisation pour mes services de domaine, le second service en doublon n'aurait peut-être jamais été créé.
Mais ces pratiques ont une limite fondamentale : elles restent non déterministes.
Une instruction dans un CLAUDE.md n'est pas une garantie d'application, c'est une indication forte que l'IA va respecter la plupart du temps ... mais pas toujours, le code généré reste sujet à interprétation surtout lorsque le contexte augmente ou que les itérations s'enchaînent.
Pour aller encore plus loin, des approches plus sophistiquées émergent : GSD, ChiefLoops, Craftsman ... ou plus directement dans Claude Code, l'orchestration d'équipes d'agents spécialisés où chaque rôle (architecte, développeur, reviewer, testeur ...) est tenu par un agent distinct.
L'idée est interessante : reproduire les dynamiques d'une équipe humaine pour obtenir une vision architecturale plus complète et plus rigoureuse.
Dans mon cas, un agent dédié à la revue architecturale aurait probablement signalé la duplication des deux services dès leur création. Un agent jouant le rôle d'architecte aurait sans doute refusé la fusion à coups de conditionnels, en imposant une séparation des responsabilités plus propre.
Ces approches produisent souvent un code de bien meilleure qualité que la génération directe et permettent de poser des cadres beaucoup plus robustes mais elles ont également un coût bien réel.
Multiplier les agents, c'est également multiplier la consommation de tokens : une simple feature peut soudainement consommer dix fois plus de tokens qu'avec une approche directe.
Ces approches montrent également leurs limites face à des contextes plus complexes : sur une application legacy aux frontières floues ou sur une feature à large périmètre, les agents peinent parfois à maintenir une vision cohérente du système et finissent souvent par produire un résultat décevant au regard de leur coût.
Ces outils existent, ils fonctionnent et sont souvent suffisants ... mais ils restent coûteux et leur sophistication peut vite excéder ce que demande réellement le projet.
Et si certains principes devenaient obsolètes ?
Il serait facile de conclure cet article par une morale convenue : l'IA n'a pas de jugement architectural, le développeur reste indispensable.
Cette conclusion serait rassurante mais probablement fausse.
Reprenons notre situation initiale : la duplication des deux services. Si l'IA peut maintenir indéfiniment des copies cohérentes, le DRY garde-t-il vraiment le même sens ?
Le principe DRY n'est pas apparu par magie, il a été formulé à une époque où les développeurs travaillaient sans assistant, sans génération automatique, et où la moindre duplication constituait un risque élevé d'incohérence à terme.
Notre charge mentale étant limitée, factoriser était autant un acte technique qu'un acte de survie cognitive.
Si l'IA peut, demain, maintenir cinquante variations cohérentes d'un même algorithme sans drift, alors la motivation originelle du DRY s'effrite.
Le principe ne disparaîtrait pas pour autant parce que la duplication pose aussi des problèmes de testabilité, de lisibilité et de traçabilité ... mais sa hiérarchie dans nos préoccupations changerait probablement.
Vous pourriez remarquer que ce raisonnement vaut aussi pour d'autres principes et vous auriez totalement raison !
Beaucoup de nos règles architecturales ont été pensées pour des cerveaux humains, contraints en mémoire et en attention, qui devaient absolument simplifier le code pour pouvoir le comprendre et le maintenir.
Une partie de notre architecture est, de fait, une longue série de béquilles destinées à compenser nos propres limites.
Pour autant, je ne pense pas que ces principes soient appelés à disparaître mais plutôt à se redéfinir.
À mesure que les IA prennent une place croissante dans la génération de code, une nouvelle contrainte architecturale émerge silencieusement : limiter l'envergure du code pour préserver le contexte de l'IA.
Plus une codebase est cohérente, modulaire et bornée par des frontières claires, plus l'IA peut en tenir une portion significative dans son contexte actif.
Mais réduire ce constat à une simple question de fenêtre de contexte serait passer à côté de l'essentiel.
Une architecture en couches bien pensée ne se contente pas de tenir dans le contexte de l'IA, elle borne son périmètre d'action.
Chaque frontière devient une garantie, chaque contrat devient une contrainte à respecter : L'IA ne peut plus dériver vers ce qui ne la concerne pas parce que le système lui même refuse cette dérive.
Et c'est probablement ici que se précise le rôle de l'architecte : il n'est plus seulement celui qui pense le code, il devient le gardien de l'évolutivité du système, celui qui préserve la souplesse nécessaire à toutes les évolutions à venir, qu'elles soient humaines ou générées.
La rigidité devient notre préoccupation principale parce qu'elle multiplie le coût de chaque modification future : à chaque frontière mal posée, à chaque couplage évitable, c'est un peu de cette souplesse qui disparaît.
Une fonction de 2000 lignes ou une fonctionnalité tentaculaire n'est plus seulement difficile à lire pour un humain, elle sature également le contexte de l'agent qui les manipule, l'obligeant à prendre des décisions partielles, diminuant sa vision globale.
Les anciennes raisons de bien architecturer ne disparaissent pas, le découplage, l'inversion de dépendance, la définition de frontières claires, tous ces principes restent valides, non plus parce qu'ils nous protègent de notre propre confusion, mais parce qu'ils protègent le contexte que nous donnons à la machine.
« The reason the code is rigid is because the modules depend on each other in undesirable ways »
— Robert C. Martin
Conclusion
L'IA n'a pas dupliqué un service par incompétence, elle l'a dupliqué parce que rien ne lui interdisait de le faire et c'est la même mécanique qui s'est rejouée à chaque dérive.
Pour briser l'inversion de dépendance, il a suffi qu'aucune frontière n'ait été posée, pour exposer une structure interne, il a suffi qu'aucun contrat ne l'ait encapsulée.
Et si, au fond, ces trois dérives n'étaient pas des erreurs de l'IA mais simplement les nôtres ?
Le métier de développeur ne consiste plus à écrire chaque ligne mais à poser les contraintes qui rendront l'IA fiable dans la durée. Plus le code devient facile à produire, plus la compréhension des enjeux d'architecture devient précieuse et essentielle.
À la vue de cette expérience se pose une dernière question : combien de nos principes architecturaux sont des vérités intemporelles et combien ne sont que des compensations à nos propres limites cognitives ?
Le futur le dira, probablement à mesure que les contextes des IA grandiront et que certaines de nos règles, devenues silencieuses, se révéleront simplement avoir été des réflexes humains déguisés en lois universelles.


Merci pour l'article. J'ai eu une réflexion en le lisant. Est ce que ces béquilles dev dont tu parles (refacto, service modulaire...) n'auraient pas un sens à être gardé si l'humain reste en contrôle du code produit. Comme une sorte de garanti. Un tampon "vérifié". Aussi je pense qu'un code bien structuré permet de faire travailler l'IA à moindre cout. Donc il y a une notion économique et écologique. Qu'en penses tu ?
Merci pour ton commentaire ! Je n'ai pas de réponse très ferme ni définitive.
Tant que l'humain est responsable du code en production, jusqu'à quel niveau doit-il être en mesure de le comprendre et de l'opérer ?
Je vois mal comment je pourrais me soustraire à une compréhension même partielle et limitée, mais ce contrôle est lui aussi une chimère qui repose sur une illusion.
Cela fait longtemps que nous avons abandonné le contrôle absolu sur le code : compilateur, framework, ORM ... l'histoire de l'informatique n'est qu'une succession de lâcher-prises, du moins pour ce que nous construisons (le web).
C'est une idée que je développe plus en profondeur dans cet article !
Tu veux commenter ? Crée un compte ou connecte-toi.
A lire
Autres articles de la même catégorie

Le vibecoding : c'est trop bien
L'arrivée du vibe coding et de l'IA ont profondément changé notre manière d'appréhender le code, voyons comment utiliser efficacement ces nouvelles technologies.
Mathieu De Gracia

Il y aura toujours des bugs
Quelqu'un qui pense qu'une application peut-être exempte de bugs est un fou.
Mathieu De Gracia

Comité Refactorisation : Améliorer le code existant
Résorbez progressivement la dette technique de votre application grâce à un comité de refactorisation
Mathieu De Gracia